


Voice interaction technology has significantly evolved with the advancements in artificial intelligence (AI). The field focuses on enhancing natural communication between humans and machines, aiming to make interactions more intuitive and human-like. Recent developments have made it possible to achieve high-precision speech recognition, emotion detection, and natural speech generation. Researchers have been creating models that can handle multiple languages and understand emotions, making interactions more seamless and human-like.
The primary challenge is the enhancement of natural voice interactions with large language models (LLMs). Current systems often need help with latency, multilingual support, and the ability to generate emotionally resonant and contextually appropriate speech. These limitations hinder seamless and human-like interactions. Enhancing the capabilities of these systems to understand and develop speech accurately across different languages and emotional contexts is crucial for advancing human-machine interaction.
Existing methods for voice interaction include various speech recognition and generation models. Tools like Whisper for speech recognition and traditional models for emotion detection and audio event classification have laid the groundwork. However, these methods often fail to provide low-latency, high-precision, and emotionally expressive interactions across multiple languages. The need for a more robust and versatile solution to handle these tasks efficiently is evident.
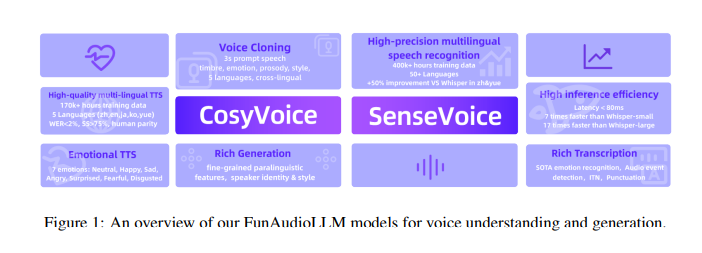
Researchers from Alibaba Group introduced FunAudioLLM, comprising two core models: SenseVoice and CosyVoice. SenseVoice excels in multilingual speech recognition, emotion recognition, and audio event detection, supporting over 50 languages. CosyVoice focuses on natural speech generation, allowing control over language, timbre, speaking style, and speaker identity. By combining these models, the research team aimed to push the boundaries of voice interaction technology.
The technology behind FunAudioLLM is built on advanced architectures for both SenseVoice and CosyVoice. SenseVoice-Small uses a non-autoregressive model for low-latency speech recognition in five languages, delivering performance over five times faster than Whisper-small and over fifteen times faster than Whisper-large. SenseVoice-Large supports speech recognition in over 50 languages, providing high precision and supporting complex tasks like emotion recognition and audio event detection. CosyVoice employs supervised semantic speech tokens for natural and emotionally expressive voice generation, which are capable of zero-shot learning and cross-lingual voice cloning.
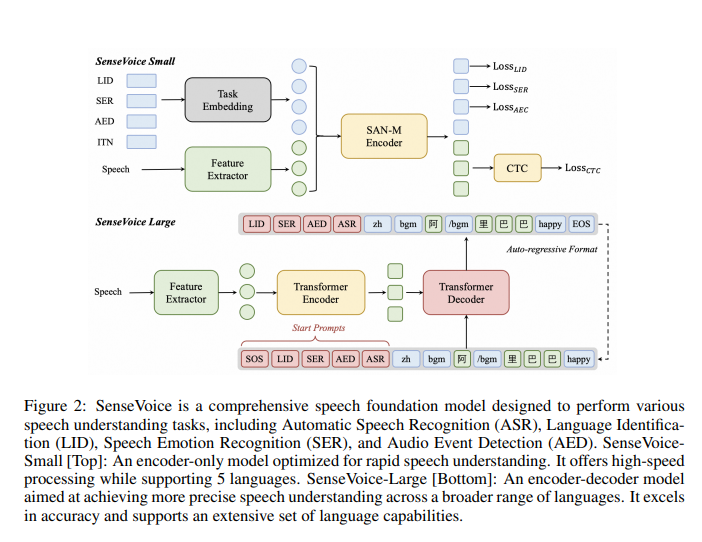
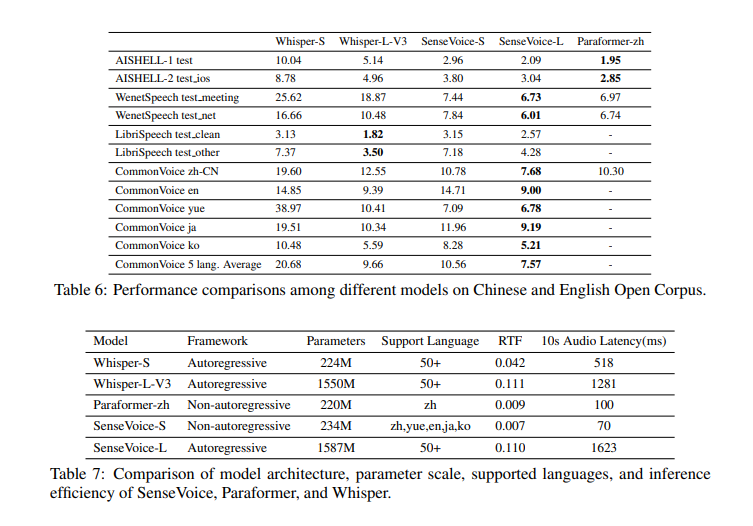
The performance of FunAudioLLM shows significant improvements over existing models. SenseVoice achieves faster and more accurate speech recognition than Whisper. For instance, SenseVoice-Small delivers a recognition latency of less than 80ms, which is significantly lower than its counterparts. SenseVoice-Large demonstrates high-precision automatic speech recognition (ASR) with a word error rate (WER) reduction of over 20% in multiple languages compared to Whisper. CosyVoice excels in generating multilingual voices tailored to specific speakers, achieving a WER of less than 2% and a speaker similarity score exceeding 75%, which matches human parity. It supports zero-shot in-context learning, allowing voice cloning with just a three-second prompt, and offers detailed control over speech output through instructional text.
To conclude, the researchers from Alibaba Group demonstrated that FunAudioLLM can be applied in various practical ways. These include speech-to-speech translation, enabling users to speak in foreign languages using their voice; emotional voice chat, where the model can understand and respond to emotions for more human-like interactions; interactive podcasts, allowing users to engage in live discussions with multiple large models; and expressive audiobook narration, providing multi-character narration for audiobooks. The integration of SenseVoice and CosyVoice with LLMs has enabled these advanced capabilities, showcasing the potential of FunAudioLLM in pushing the boundaries of voice interaction technology.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post FunAudioLLM: A Multi-Model Framework for Natural, Multilingual, and Emotionally Expressive Voice Interactions appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Sound #Staff #TechNews #Technology [Source: AI Techpark]