


One of the most exciting advancements in AI and machine learning has been speech generation using Large Language Models (LLMs). While effective in various applications, the traditional methods face a significant challenge: the integration of semantic and perceptual information, often resulting in inefficiencies and redundancies. This is where SpeechGPT-Gen, a groundbreaking method introduced by researchers from Fudan University, comes into play.
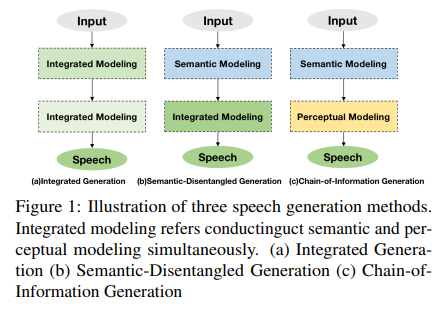
SpeechGPT-Gen, developed using the Chain-of-Information Generation (CoIG) method, represents a significant change in the approach to speech generation. The traditional integrated semantic and perceptual information modeling often led to inefficiencies, akin to trying to paint a detailed picture with broad, overlapping strokes. In contrast, CoIG, like using separate brushes for different elements in a painting, ensures that each aspect of speech – semantic and perceptual – is given attention.
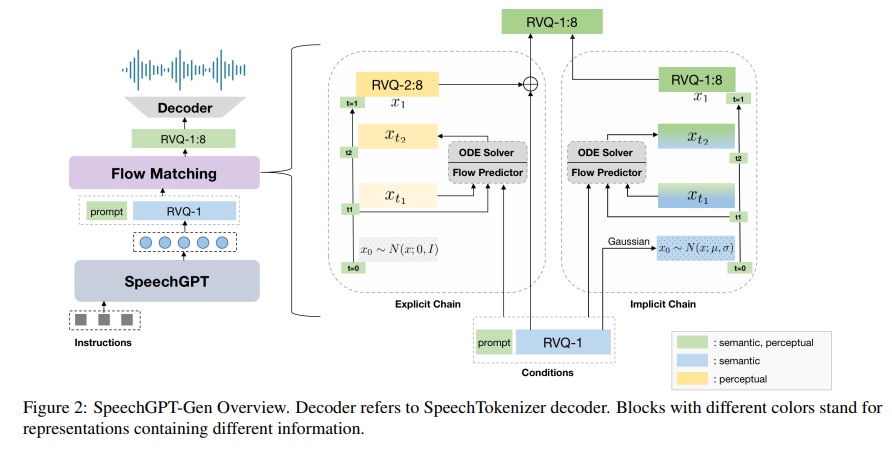
The methodology of SpeechGPT-Gen is fascinating in its approach. It utilizes an autoregressive model based on LLMs for semantic information modeling. This part of the model deals with speech’s content, meaning, and context. On the other hand, a non-autoregressive model employing flow matching is used for perceptual information modeling, focusing on the nuances of speech, such as tone, pitch, and rhythm. This distinct separation allows for a more refined and efficient speech processing, significantly reducing the redundancies plaguing traditional methods.
In zero-shot text-to-speech, the model achieves lower Word Error Rates (WER) and maintains a high degree of speaker similarity. This indicates its sophisticated semantic modeling capabilities and ability to maintain individual voices’ uniqueness. In zero-shot voice conversion and speech-to-speech dialogue, the model again demonstrates its superiority, outperforming traditional methods regarding content accuracy and speaker similarity. This success in diverse applications showcases SpeechGPT-Gen’s practical effectiveness in real-world scenarios.
A particularly notable aspect of SpeechGPT-Gen is its use of semantic information as a prior in flow matching. This innovation marks a significant improvement over standard Gaussian methods, enhancing the model’s efficiency in transforming from a simple prior distribution to a complex, real data distribution. This approach not only improves the accuracy of the speech generation but also contributes to the naturalness and quality of the synthesized speech.
SpeechGPT-Gen exhibits excellent scalability. As the model size and the amount of data it processes increase, it consistently decreases training loss and improves performance. This scalability is essential for adapting the model to various requirements, ensuring that it remains effective and efficient as the scope of its application expands.
In conclusion, the research conducted can be presented in a nutshell:
- SpeechGPT-Gen addresses inefficiencies in traditional speech generation methods.
- The Chain-of-Information Generation method separates semantic and perceptual information processing.
- The model shows remarkable results in zero-shot text-to-speech, voice conversion, and speech-to-speech dialogue.
- Semantic information in flow matching enhances the model’s efficiency and output quality.
- SpeechGPT-Gen demonstrates impressive scalability, which is vital for its adaptation to diverse applications.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Fudan University Researchers Introduce SpeechGPT-Gen: A 8B-Parameter Speech Large Language Model (SLLM) Efficient in Semantic and Perceptual Information Modeling appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]