


Generative vision-language models (VLMs) have revolutionized radiology by automating the interpretation of medical images and generating detailed reports. These advancements hold promise for reducing radiologists’ workloads and enhancing diagnostic accuracy. However, VLMs are prone to generating hallucinated content—nonsensical or incorrect text—which can lead to clinical errors and increased workloads for healthcare professionals.
The core issue is the tendency of VLMs to hallucinate references to prior exams in radiology reports. Incorrect references to past images can mislead clinicians, complicate patient care, and necessitate additional verification and correction efforts by radiologists. This problem is particularly acute in chest X-ray report generation, where such hallucinations can obscure critical clinical information and increase the risk of patient harm if not corrected.
Traditional methods for mitigating hallucinations in generative models include preprocessing training datasets to remove problematic references. This approach, while effective, is resource-intensive and cannot correct issues that arise post-training. Reinforcement learning with human feedback (RLHF) offers an alternative by aligning model outputs with human preferences, but it requires complex reward models. Direct Preference Optimization (DPO), a simpler and more efficient method derived from RLHF, is proposed in this paper to suppress unwanted behaviors in pretrained models without needing explicit reward models.

Researchers from Harvard University, Jawaharlal Institute of Postgraduate Medical Education & Research, and Johns Hopkins University have proposed a DPO-based method specifically tailored for suppressing hallucinated references to prior exams in chest X-ray reports. By fine-tuning the model using DPO, the team significantly reduced these unwanted references while maintaining clinical accuracy. The method involves using a subset of the MIMIC-CXR dataset, edited to remove references to prior exams, for training and evaluation. This subset was carefully curated to ensure it could effectively train the model to recognize and avoid generating hallucinatory content.
The proposed method employs a vision-language model pretrained on MIMIC-CXR data. The VLM architecture includes a vision encoder, a vision-language adapter, and a language model. The vision encoder converts input images into visual tokens, which the adapter maps to the language space. These tokens are processed through the language model, which generates the chest X-ray report. Specifically, the model uses a Swin Transformer as the vision encoder and Llama2-Chat-7b as the language model, with parameter-efficient tuning using LoRA.
The fine-tuning process involves creating preference datasets where preferred responses avoid references to prior exams, and dispreferred responses include such references. These datasets train the model with weighted DPO losses, emphasizing the suppression of hallucinated content. The training set included 19,806 studies, while the validation set comprised 915. The test set consisted of 1,383 studies. The DPO training dataset was built by identifying dispreferred reports referencing prior exams and creating preferred versions by removing these references using GPT-4.
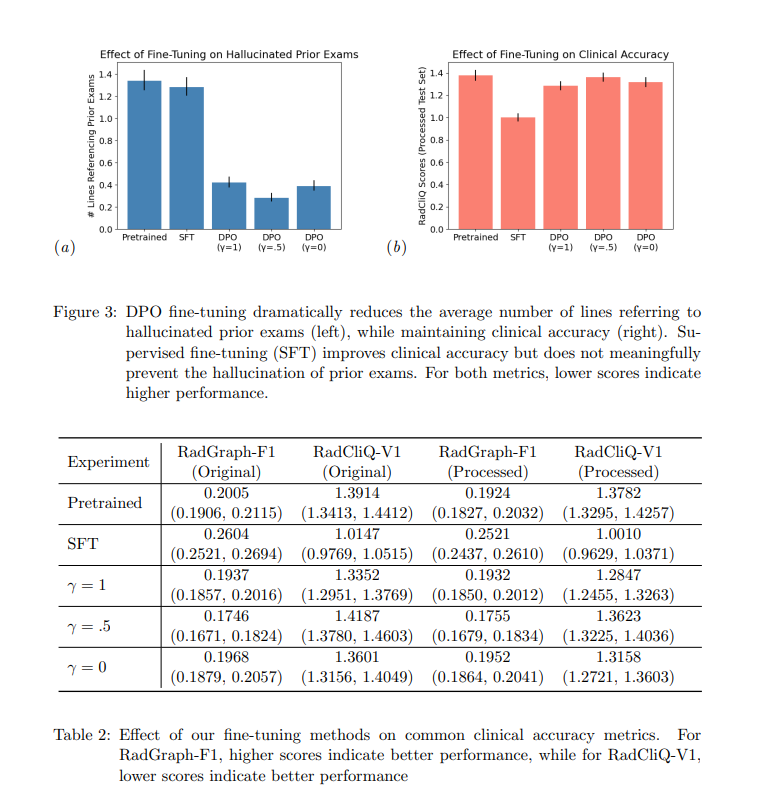
The performance of the fine-tuned models was evaluated using several metrics. The results showed a significant reduction in hallucinated references, with models trained using DPO exhibiting a 3.2 to 4.8-fold decrease in such errors. Specifically, the best-performing DPO model reduced the average number of lines referring to prior exams per report from 1.34 to 0.28 and halved the proportion of reports mentioning prior exams from 50% to about 20%. The clinical accuracy of the models, assessed using metrics like RadCliq-V1 and RadGraph-F1, remained high. For instance, the RadCliq-V1 score for the best DPO model was 1.3352 compared to 1.3914 for the original pretrained model, indicating improved alignment with radiologist preferences without compromising accuracy.
In conclusion, the research demonstrates that DPO can effectively suppress hallucinated content in radiology report generation while preserving clinical accuracy. This approach offers a practical and efficient solution to improve the reliability of AI-generated medical reports, ultimately enhancing patient care and reducing the burden on radiologists. The findings suggest that integrating DPO into VLMs can significantly improve their utility in clinical settings, making AI-generated reports more trustworthy and valuable.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post From Phantoms to Facts: DPO Fine-Tuning Minimizes Hallucinations in Radiology Reports, Boosting Clinical Trust appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]