


Deep features are pivotal in computer vision studies, unlocking image semantics and empowering researchers to tackle various tasks, even in scenarios with minimal data. Lately, techniques have been developed to extract features from diverse data types like images, text, and audio. These features serve as the bedrock for various applications, from classification to weakly supervised learning, semantic segmentation, neural rendering, and the cutting-edge field of image generation. With their transformative potential, deep features continue to push the boundaries of what’s possible in computer vision.
Although deep features have many applications in computer vision, they often need more spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction due to models that aggressively pool information by models over large areas. For instance, ResNet-50 condenses a 224 × 224-pixel input to 7 × 7 deep features. Even the cutting-edge Vision Transformers (ViTs) face similar challenges, significantly reducing resolution. This reduction presents a hurdle in leveraging these features for tasks demanding precise spatial information, such as segmentation or depth estimation.
A group of researchers from MIT, Google, Microsoft, and Adobe introduced FeatUp, a task and model-agnostic framework that restores lost spatial information in deep features. They gave two variants of FeatUp: the first one guides features with a high-resolution signal in a single forward pass. In contrast, the second one fits an implicit model to a single image to reconstruct features at any resolution. These features retain their original semantics and can seamlessly replace existing features in various applications to yield resolution and performance gains even without re-training. FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, depth prediction, etc.
For FeatUp variants, a multi-view consistency loss with deep analogies to NeRFs has been used. The following steps are considered in this research paper while developing FeatUp:
- Generated low-resolution feature views to refine into a single high-resolution output. For this, the input image was perturbed with small pads and horizontal flips. The model was applied to each transformed image to extract a collection of low-resolution feature maps from these views. It provides sub-feature information to train the upsampler.
- We constructed a consistent high-resolution feature map and postulated that it can reproduce low-resolution jittered features when downsampled. FeatUp’s downsampling is a direct analog to ray-marching, which transforms high-resolution into low-resolution features.
- Upsamplers are trained on the ImageNet training set for 2,000 steps, and metrics are computed across 2,000 random images from the validation set. A frozen pre-trained ViT-S/16 also served as the feature, extracting Class Activation Maps (CAMs) by applying a linear classifier after max-pooling.
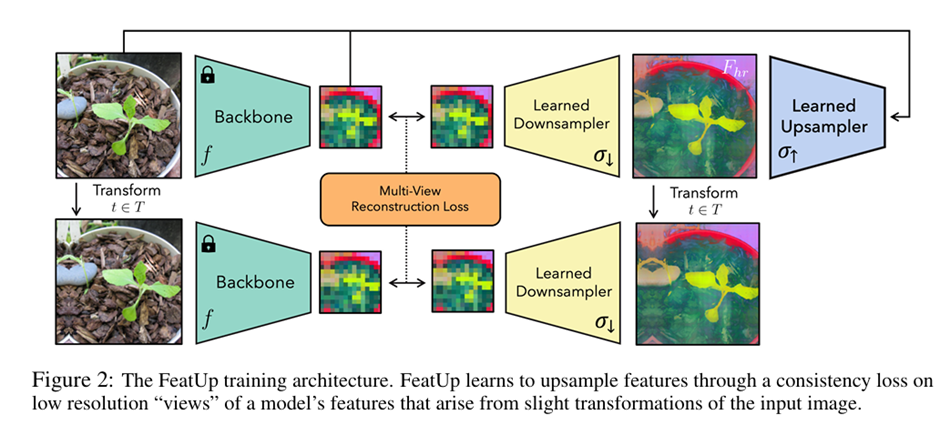
On comparing downsampled features with the true model outputs using a Gaussian likelihood loss, it is observed that a good high-resolution feature map should reconstruct the observed features across all the different views. To reduce the memory footprint and further speed up the training of FeatUp’s implicit network, the spatially varying features are compressed to their top k=128 principal components. This compression operation maintains nearly all relevant information, as the top 128 components explain approximately 96% of the variance in a single image’s features. This optimization accelerates training time by a remarkable 60× for models like ResNet-50 and facilitates larger batches without compromising feature quality.
In conclusion, FeatUp, a task and model-agnostic framework that restores lost spatial information in deep features, is a novel approach to upsample deep features using multi-view consistency. It can learn high-quality features at arbitrary resolutions. It solves a critical problem in computer vision: deep models learn high-quality features but at prohibitively low spatial resolutions. Both variants of FeatUp outperform a wide range of baselines across linear probe transfer learning, model interpretability, and end-to-end semantic segmentation.
Check out the Paper and MIT Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post FeatUp: A Machine Learning Algorithm that Upgrades the Resolution of Deep Neural Networks for Improved Performance in Computer Vision Tasks appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #MachineLearning #MIT #Staff #TechNews #Technology #UniversityResearch [Source: AI Techpark]