


Large Language Models (LLMs) represent a significant leap in artificial intelligence, offering robust natural language understanding and generation capabilities. These advanced models can perform various tasks, from aiding virtual assistants to generating comprehensive content and conducting in-depth data analysis. Despite their impressive range of applications, LLMs face a critical challenge in generating factually accurate responses, often producing misleading or inaccurate information due to the broad spectrum of data they process. This is a notable concern, especially considering their intended use in providing reliable information.
One of the main issues with LLMs is their tendency to hallucinate, which means they generate fabricated or incorrect information. This problem is primarily rooted in the supervised fine-tuning (SFT) and reinforcement learning (RL) processes, which unintentionally encourage these models to produce misleading outputs. As LLMs are designed to respond to diverse user queries, it’s crucial to ensure they produce accurate information to prevent the spread of misinformation. The challenge lies in aligning these models to deliver factually correct responses without compromising their instruction-following ability.
Traditional methods like SFT and RL with human feedback (RLHF) have focused on enhancing the ability of LLMs to follow instructions effectively. However, these methods tend to prioritize more detailed and longer responses, which often leads to increased hallucinations. Research has shown that fine-tuning models with new or unfamiliar information exacerbate this problem, making them more prone to generating unreliable content. As a result, there’s a pressing need for approaches that can improve the factual accuracy of these models without negatively affecting their instruction-following capabilities.
Researchers from the University of Waterloo, Carnegie Mellon University, and Meta AI have introduced a novel approach called Factuality-Aware Alignment (FLAME) to tackle this issue. This method specifically addresses the challenge of improving factual accuracy in LLMs through a combination of factuality-aware SFT and RL with direct preference optimization (DPO). FLAME’s innovative approach focuses on crafting training data that encourages models to produce more factual responses while using specialized reward functions to steer them toward accurate outputs. They conducted a pilot study to evaluate the effectiveness of this approach using a biography generation task. The study revealed that LLMs trained on their own generated data are more reliable than those trained on more factual responses generated by other models.
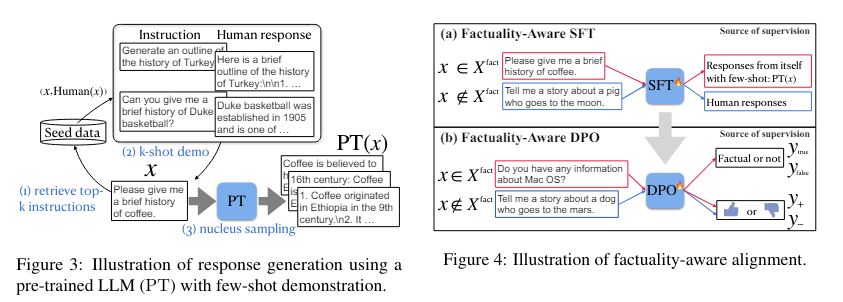
FLAME’s two-step approach begins by identifying fact-based instructions that require factual responses. Once these instructions are identified, the method fine-tunes the model using a factuality-aware SFT strategy, which prevents the model from being trained on unfamiliar information that could lead to hallucination. The second step involves implementing DPO, which uses factuality-specific rewards to differentiate between fact-based and non-fact-based instructions, guiding the LLMs to produce more reliable responses. In this way, FLAME helps LLMs maintain their instruction-following ability while significantly reducing the likelihood of hallucination.
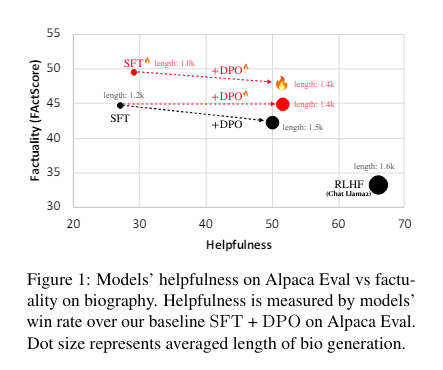
The research showed that this approach significantly improved LLMs’ factual accuracy, achieving a +5.6-point increase in FActScore compared to standard alignment processes without sacrificing instruction-following capabilities. This was validated using Alpaca Eval, a benchmark that assesses a model’s ability to follow instructions, and the Biography dataset, which evaluates the factuality of generated content. The study used 805 instruction-following tasks from Alpaca Eval to measure the win rate of models using FLAME, demonstrating the method’s effectiveness in balancing factuality with the ability to follow instructions.
In conclusion, FLAME offers a promising solution to one of the most significant challenges facing LLMs today. By refining the training and optimization process, the research team has developed a methodology that allows LLMs to follow instructions effectively while significantly reducing the risk of hallucination. This makes them better suited for applications where accuracy is paramount, allowing for more reliable AI-driven solutions in the future.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
The post Factuality-Aware Alignment (FLAME): Enhancing Large Language Models for Reliable and Accurate Responses appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]