


Studying scaling laws in large language models (LLMs) is crucial for enhancing machine translation performance. Understanding these relationships is necessary for optimizing LLMs, enabling them to learn from vast datasets and improve in tasks such as language translation, thereby pushing the boundaries of what’s achievable with current computational resources and data availability.
Of all the major challenges associated with the field, a key challenge in advancing LLMs is determining the effect of pretraining data size and its alignment with downstream tasks, particularly in machine translation. The intricacies of how pretraining on diverse datasets influences model performance on specific tasks still need to be explored. This issue is critical since the pretraining phase significantly affects the model’s ability to understand and translate languages effectively.
Present strategies for enhancing LLM performance mainly focus on adjusting the size of the pretraining datasets and the model architecture. These methods employ upstream metrics like perplexity or cross-entropy loss to gauge model improvements during pretraining. However, these metrics may not directly translate to better performance on downstream tasks such as translation. Thus, there’s a pressing need for more targeted approaches that consider the downstream task performance, specifically looking at metrics like BLEU scores, which more accurately reflect the translation quality of models.
Researchers from Stanford University and Google Research have developed new scaling laws that predict the translation quality of LLMs based on pretraining data size. These laws illustrate that the BLEU score adheres to a log while cross-entropy follows a power law. They highlight that cross-entropy may not reliably indicate downstream performance, with BLEU score trends providing a more accurate assessment of the value of pretraining data. This framework offers a method to evaluate whether pretraining aligns with the task, guiding effective data utilization for enhancing model performance.
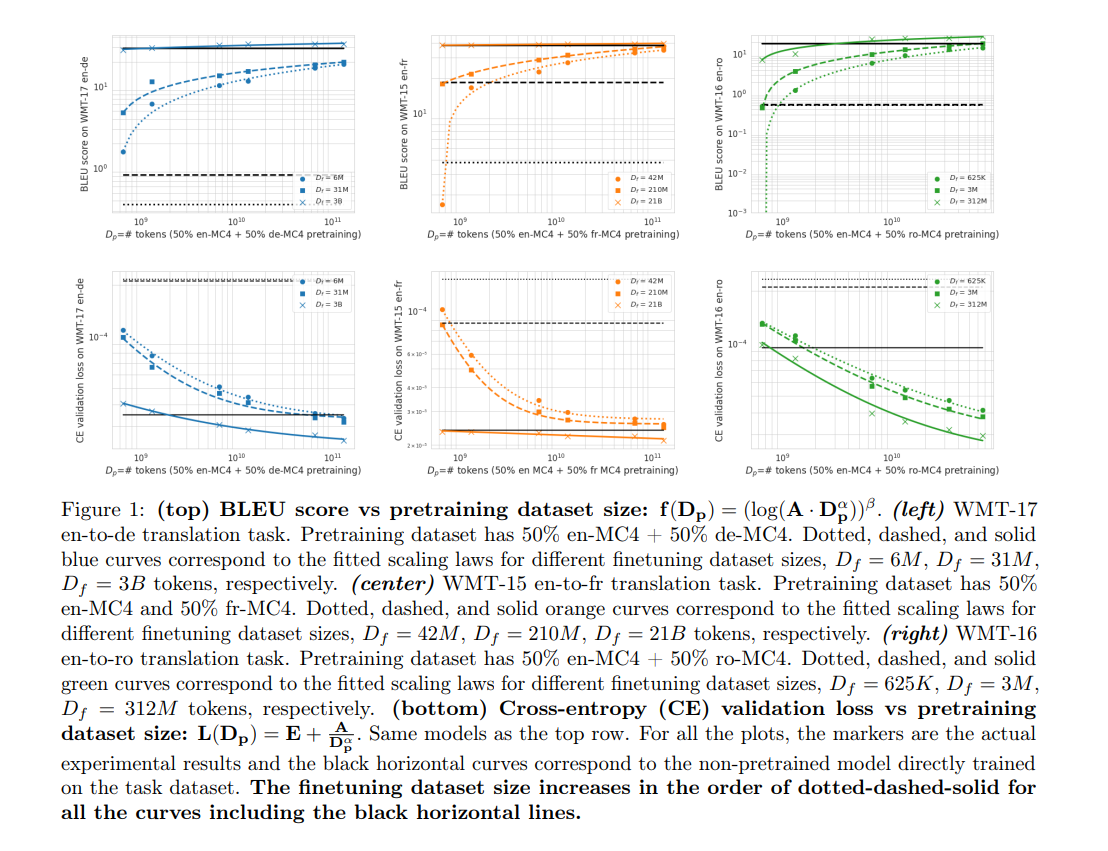
The research utilizes a 3-billion T5 encoder-decoder model pretraining on MC4 dataset sections (English, German, French, Romanian), followed by finetuning on selected checkpoints. It investigates translation tasks across varying dataset sizes, employing specific hyperparameters like batch size and learning rate. Results include scaling law coefficients optimized via Huber loss and L-BFGS algorithm, with prediction errors detailed in appendices. This experimental framework underscores the nuanced impact of pretraining data size and alignment on translation performance.
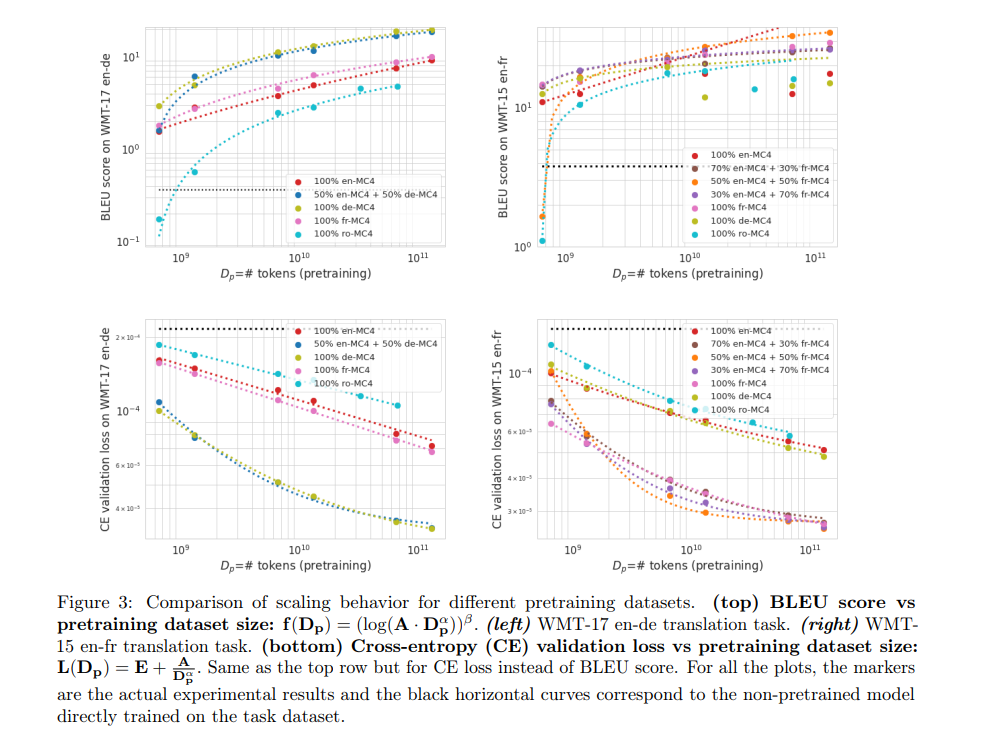
The results reveal that larger finetuning datasets improve BLEU scores and reduce cross-entropy loss, especially notable in smaller datasets where pretraining’s influence is significant. Pretraining proves redundant with ample finetuning data. Misaligned pretraining datasets adversely affect performance, emphasizing the importance of data alignment. English-to-German translations exhibit consistent metric correlations, unlike English-to-French, questioning cross-entropy’s reliability as a performance indicator. Pretraining benefits vary by language, with German or French showing advantages over English, indicating the nuanced effectiveness of scaling laws in predicting model behavior across different translation tasks.
In conclusion, by introducing and validating new scaling laws, the research team provides a valuable framework for predicting model performance, offering a pathway to more effective and efficient model training. The study’s revelations about the critical role of data alignment in achieving optimal model performance illuminate a path forward for future research and development in LLMs, highlighting the potential for these models to revolutionize language translation through informed and strategic data utilization.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Exploring the Scaling Laws in Large Language Models For Enhanced Translation Performance appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]