


Large Language Models (LLMs) signify a revolutionary leap in numerous application domains, facilitating impressive accomplishments in diverse tasks. Yet, their immense size incurs substantial computational expenses. With billions of parameters, these models demand extensive computational resources for operation. Adapting them to specific downstream tasks becomes particularly challenging due to their vast scale and computational requirements, especially on hardware platforms limited by computational capabilities.
Previous studies have proposed that LLMs demonstrate considerable generalization abilities, allowing them to apply learned knowledge to new tasks not encountered during training, a phenomenon known as zero-shot learning. However, fine-tuning remains crucial to optimize LLM performance on robust user datasets and tasks. One widely adopted fine-tuning strategy involves adjusting a subset of LLM parameters while leaving the rest unchanged, termed Parameter-Efficient Fine-Tuning (PEFT). This technique selectively modifies a small fraction of parameters while keeping the majority untouched. PEFT’s applicability extends beyond Natural Language Processing (NLP) to computer vision (CV), garnering interest in fine-tuning large-parameter vision models like Vision Transformers (ViT) and diffusion models, as well as interdisciplinary vision-language models.
Researchers from Northeastern University, the University of California, Arizona State University, and New York University present this survey thoroughly examining diverse PEFT algorithms and evaluating their performance and computational requirements. It also provides an overview of applications developed using various PEFT methods and discusses common strategies employed to reduce computational expenses associated with PEFT. Beyond algorithmic considerations, the survey delves into real-world system designs to explore the implementation costs of different PEFT algorithms. As an invaluable resource, this survey equips researchers with insights into PEFT algorithms and their system implementations, offering detailed analyses of recent progressions and practical uses.
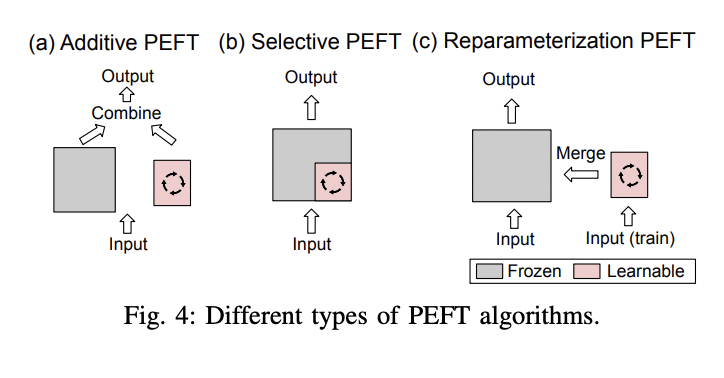
The researchers categorized PEFT algorithms into additive, selective, reparameterized, and hybrid fine-tuning based on their operations. Major additive fine-tuning algorithms include adapters, soft prompts, and others, which differ in the additional tunable modules or parameters they utilize. Selective fine-tuning, in contrast, involves selecting a small subset of parameters from the backbone model, making only these parameters tunable while leaving the majority untouched during downstream task fine-tuning. Selective fine-tuning is categorized based on the grouping of chosen parameters: Unstructural Masking and Structural Masking. Reparametrization involves transforming model parameters between two equivalent forms, introducing additional low-rank trainable parameters during training, which are then integrated with the original model for inference. This approach encompasses two main strategies: Low-rank Decomposition and LoRA Derivatives. Hybrid fine-tuning explores different PEFT methods’ design spaces and combines their advantages.
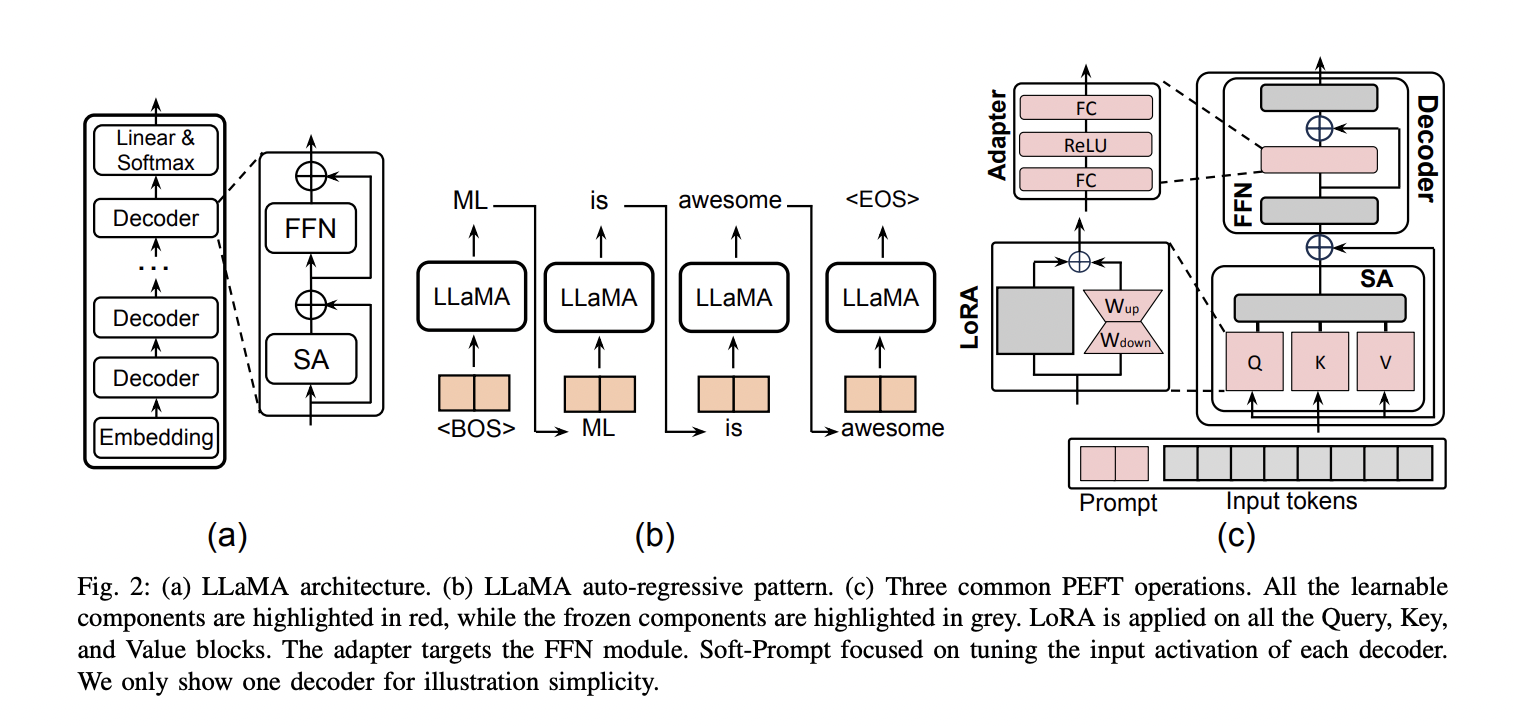
They established a series of parameters to examine computation costs and memory overhead in LLMs as a foundation for subsequent analysis. In LLMs, tokens (words) are generated iteratively based on the preceding prompt (input) and previously generated sequence. This process continues until the model outputs a termination token. A common strategy to expedite inference in LLMs involves storing previous Keys and Values in a KeyValue cache (KV-cache), eliminating the need to recalculate them for each new token.
To conclude, this survey comprehensively explores diverse PEFT algorithms, providing insights into their performance, applications, and implementation costs. By categorizing PEFT methods and examining computation and memory considerations, this study offers invaluable guidance for researchers traversing the complexities of fine-tuning large models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post Exploring Parameter-Efficient Fine-Tuning Strategies for Large Language Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]