


In artificial intelligence, large language models (LLMs) are a beacon of innovation, ushering in an era where autonomous agents can perform complex tasks with unprecedented precision. These models, including renowned examples like GPT-4, enable agents to plan and execute actions within diverse environments, from web browsing to multi-modal reasoning. Yet, for all their capabilities, a gap remains in these agents’ ability to learn from their experiences, particularly from the trials that end not in success but in failure.
The training of these agents has been anchored in the successes, imitating the paths that led to the desired outcomes without fully considering the instructive potential of the roads that led astray. While effectively replicating known paths to success, this approach must be revised in teaching agents the resilience and adaptability required to navigate uncharted or dynamic environments.
A research team from Allen Institute for AI; School of Computer Science, Peking University; National Key Laboratory for Multimedia Information Processing, Peking University; UCLA; Ohio State University, and UIUC introduced an innovative Exploration-based Trajectory Optimization (ETO) method. This method departs from conventional training paradigms by integrating the learning from unsuccessful attempts, thus broadening the agents’ experiential learning and enhancing their problem-solving capabilities.
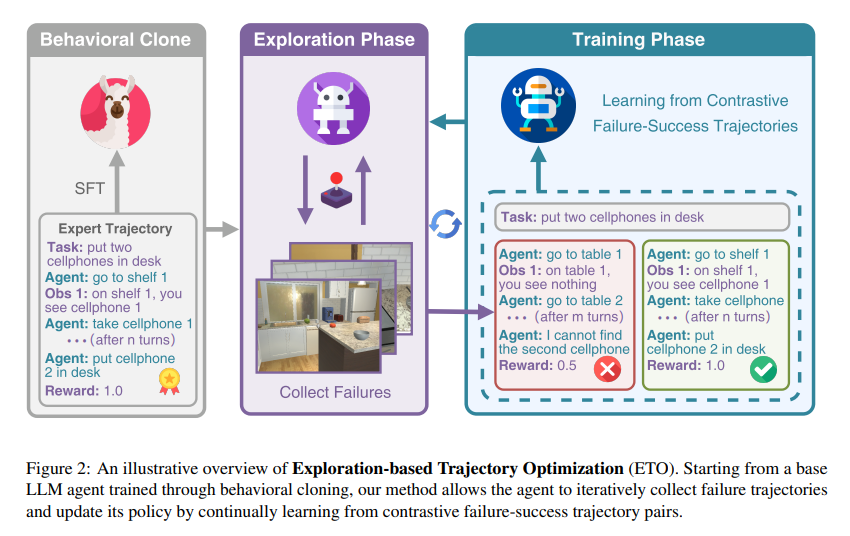
At the heart of ETO lies a sophisticated learning algorithm that enriches the agents’ training with a nuanced understanding of both success and failure. Initially, agents undergo training with successful trajectories, establishing a foundational strategy for task completion. The innovation of ETO unfolds in the exploration phase, where agents interact with their environment, deliberately engaging in tasks that result in failed attempts. These failures, far from being dismissed, are collected and paired with successful trajectories, creating a rich dataset for contrastive learning.
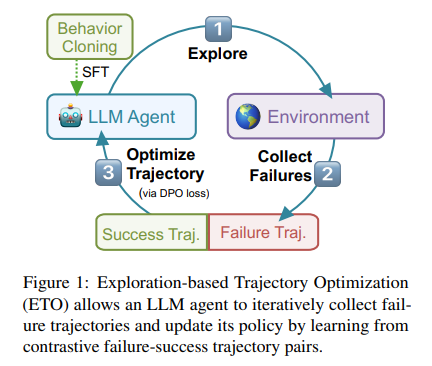
This dataset serves as the groundwork for a nuanced training phase, wherein agents learn to discern between effective and ineffective strategies through the lens of contrastive failure-success pairs. Employing a method known as contrastive learning, ETO iteratively optimizes the agents’ decision-making processes. This cycle of exploration and learning enables agents to replicate success and to navigate and adapt to the complexities and unpredictabilities of their environments.
The efficacy of ETO is not just a claim but a proven fact demonstrated through rigorous experiments across a spectrum of tasks, from web navigation to simulated science experiments and household tasks. In these tests, ETO consistently outshines traditional training methods, illustrating a significant leap in performance. The method showcases a profound improvement in agents’ ability to tackle unseen and out-of-distribution tasks, a testament to its robust adaptability and generalization capabilities.
This exploration-based approach, championed by the research team, ignites excitement for the future of autonomous agents. By harnessing the full spectrum of experiential learning, including the invaluable lessons hidden within failures, ETO paves the way for the creation of more resilient, adaptable, and intelligent agents. These agents, equipped with the ability to learn from every turn of their journey, stand poised to navigate the complexities of the real world with unprecedented competence.
In conclusion, the introduction of Exploration-based Trajectory Optimization (ETO) signifies a pivotal shift in the training of autonomous agents. By embracing the dual teachers of success and failure, ETO enriches the learning landscape for LLM agents, enabling them to evolve into more adaptable, efficient, and capable entities. This advancement enhances individual agents’ performance and contributes to the broader goal of developing AI that can more effectively understand and interact with the complexities of the real and virtual worlds. Through the lens of ETO, autonomous agents’ future looks brighter and infinitely more adaptable.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Exploration-Based Trajectory Optimization: Harnessing Success and Failure for Enhanced Autonomous Agent Learning appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]