


Instruction-tuned LLMs can handle various tasks using natural language instructions, but their performance is sensitive to how instructions are phrased. This issue is critical in healthcare, where clinicians, who may need to be more skilled, prompt engineers, need reliable outputs. The robustness of LLMs to variations in clinical task instructions is thus questioned. Despite advancements in zero-shot task execution by models like GPT-3.5+, FLAN, Alpaca, and Mistral, their sensitivity to instruction phrasing poses challenges, especially in specialized domains like medicine, where inconsistent model performance can have significant consequences for patient care.
Researchers from Northeastern University and Codametrix collected prompts from medical doctors across various tasks to evaluate the sensitivity of seven general and specialized LLMs to natural instruction phrasings. They found substantial performance variability across all models, with domain-specific models trained on clinical data being particularly brittle. Differences in phrasing also affected fairness, with performance discrepancies observed between demographic groups in tasks like mortality prediction. The study highlights the robustness challenge in clinical LLMs and its implications for fairness, emphasizing the need for further research in this area. The researchers have released their code and prompts to support ongoing investigations.
Instruction-following LLMs have been enhanced to solve various tasks with minimal examples or instructions, thanks to techniques like Reinforcement Learning from Human Feedback and fine-tuning with labeled data. Large datasets for instruction tuning, such as Flan 2021 and Super-NaturalInstructions, have been created. However, LLMs are sensitive to prompt construction, affecting performance in few-shot and zero-shot settings. General LLMs can handle clinical tasks, but smaller, fine-tuned models often perform better. Privacy issues limit high-quality clinical datasets, leading researchers to use synthetic data, though general models usually outperform specialized ones.
The study examines the robustness of LLMs to natural variations in instructional phrasings for clinical tasks. It involves ten clinical classification tasks and six information extraction tasks using data from MIMIC-III, i2b2, and n2c2 challenges. A diverse group of medical professionals wrote prompts for each task. Seven LLMs, including general-domain and domain-specific models, were evaluated for performance, variance, and fairness across these prompts. Models were assessed using zero-shot inference with specific sequence lengths, processing notes in chunks. AUROC scores for classification tasks and F1 scores for extraction tasks were reported to measure effectiveness.
Results for Mortality Prediction and Drug Extraction reveal significant variability in performance due to different yet semantically equivalent instructions. In Mortality Prediction, LLAMA 2 (13B) outperformed other models, while MISTRAL showed superior performance in other classification tasks. In Drug Extraction, LLAMA 2 (7B) performed best on average, though clinical models exhibited mixed results. Analysis of demographic subgroup performance indicated disparities, with non-White and female patients often receiving lower predictive accuracy. This variability in prompts affects fairness, highlighting that minor changes in phrasing can disproportionately impact certain demographic groups. General domain models generally outperformed clinical models across tasks.
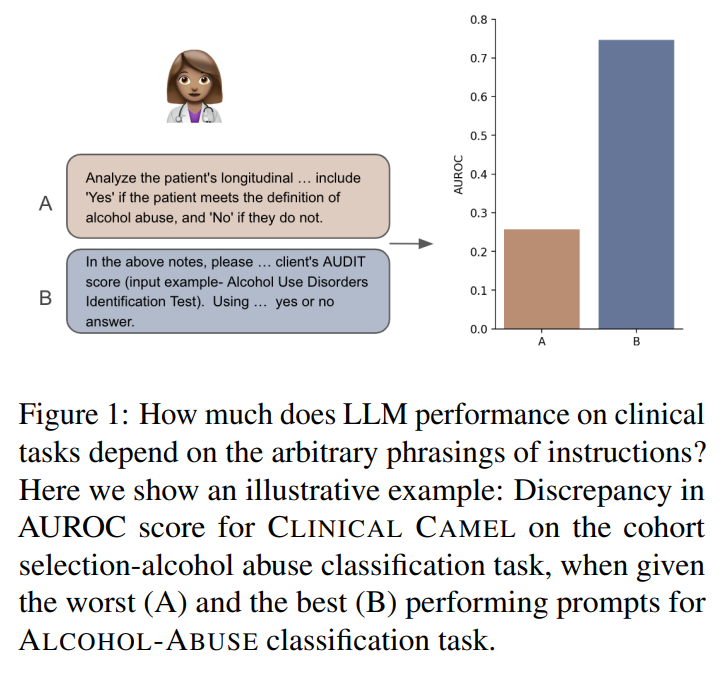
In conclusion, the study evaluates instruction-tuned open-source LLMs for clinical classification and information extraction tasks on EHR clinical notes, focusing on robustness to variations in prompts from medical professionals. Twelve practitioners from diverse backgrounds wrote prompts for 16 clinical functions. Key findings include: LLM performance varies significantly across prompts from different experts; domain-specific models generally underperform compared to general models; and prompt variations impact fairness, leading to varying levels of fairness in outcomes. Practitioners should be cautious with instruction-tuned LLMs in critical clinical tasks, as minor phrasing differences can significantly affect outputs. This highlights the need for improved LLM robustness.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
The post Evaluating the Robustness and Fairness of Instruction-Tuned LLMs in Clinical Tasks: Implications for Performance Variability and Demographic Fairness appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]