


Self-supervised features are central to modern machine learning, typically requiring extensive human effort for data collection and curation, similar to supervised learning. Self-supervised learning (SSL) allows models to be trained without human annotations, enabling scalable data and model expansion. However, scaling efforts have sometimes resulted in subpar performance due to issues like the long-tail distribution of concepts in uncurated datasets. Successful SSL applications involve careful data curation, such as filtering internet data to match high-quality sources like Wikipedia for language models or balancing visual concepts for image models. This curation enhances robustness and performance in downstream tasks.
Researchers from FAIR at Meta, INRIA, Université Paris Saclay, and Google address the automatic curation of high-quality datasets for self-supervised pre-training. They propose a clustering-based approach to create large, diverse, balanced datasets. This method involves hierarchical k-means clustering on a vast data repository and balanced sampling from these clusters. Experiments across web images, satellite images, and text demonstrate that features trained on these curated datasets outperform those trained on uncurated data, matching or exceeding manually curated data. This approach addresses the challenge of balancing datasets to improve model performance in self-supervised learning.
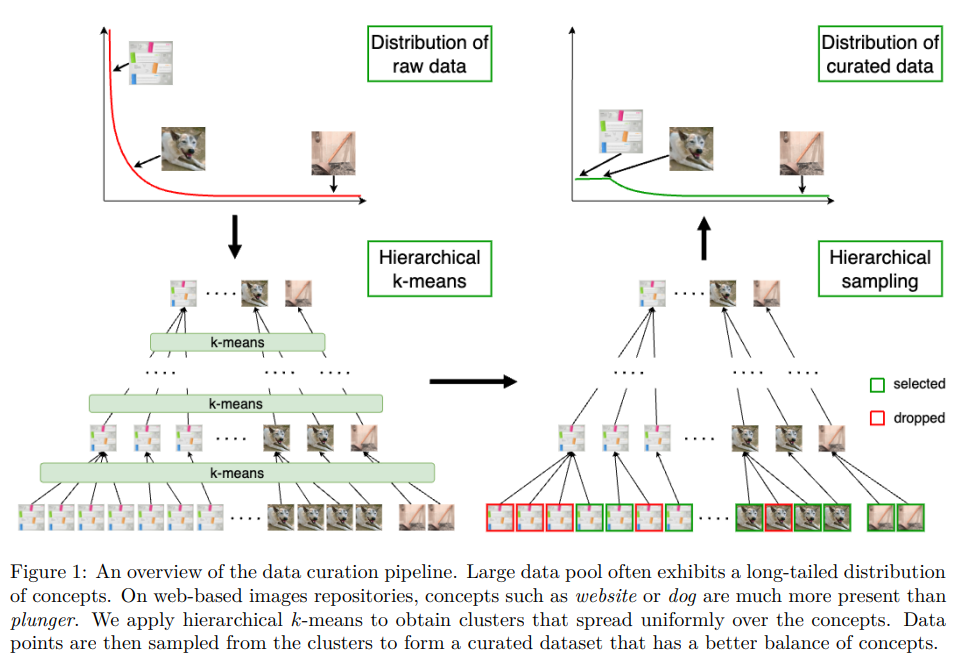
SSL is crucial in modern machine learning. In natural language processing (NLP), language modeling has evolved from simple neural architectures to large-scale models, significantly advancing the field. Similarly, SSL in computer vision has progressed from pretext tasks to sophisticated joint embedding architectures, employing methods like contrastive learning, clustering, and distillation. High-quality data is essential for training state-of-the-art models. Automatic data curation techniques, such as hierarchical k-means clustering, are proposed to balance large datasets without requiring labels, improving the performance of SSL models across various domains.
The pre-training dataset must be large, diverse, and balanced to train models effectively using self-supervised learning. Balanced datasets ensure each concept is equally represented, avoiding biases toward dominant concepts. Creating such datasets involves selecting balanced subsets from large online repositories, often using clustering methods like k-means. However, standard k-means may over-represent dominant concepts. To address this, hierarchical k-means with resampling can be used, ensuring centroids follow a uniform distribution. This process, combined with specific sampling strategies, helps maintain balance across various conceptual levels in the dataset, promoting better model performance.
Four experiments were conducted to study the proposed algorithm. Initially, simulated data was used to illustrate hierarchical k-means, showing a more uniform cluster distribution than other methods. Next, web-based image data was curated, resulting in a dataset of 743 million images, and a ViT-L model was trained and evaluated on various benchmarks, demonstrating improved performance. The algorithm was then applied to curate text data for training large language models, yielding significant gains across benchmarks. Lastly, satellite images were curated for tree canopy height prediction, enhancing model performance on all evaluated datasets.
In conclusion, The study introduces an automatic data curation pipeline that generates large, diverse, and balanced training datasets for self-supervised feature learning. By successively applying k-means clustering and resampling, the method ensures uniform cluster distribution among concepts. Extensive experiments show that this pipeline enhances feature learning across web-based images, satellite imagery, and text data. The curated datasets outperform raw data and ImageNet1k in robustness but slightly lags behind the heavily curated ImageNet22k on certain benchmarks. The approach highlights the importance of data curation in self-supervised learning and suggests hierarchical k-means as a valuable alternative in various data-dependent tasks. Future work should address dataset quality, reliance on pre-trained features, and scalability. Automated dataset creation poses risks such as reinforcing biases and privacy breaches, mitigated here by blurring human faces and striving for concept balance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Enhancing Self-Supervised Learning with Automatic Data Curation: A Hierarchical K-Means Approach appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]