


Biomedical research relies heavily on precisely identifying and classifying specialized terms from extensive textual data. This process, known as named entity recognition (NER), is fundamental for efficiently sorting and utilizing information within medical literature. Accurately extracting these entities from texts enables researchers and healthcare professionals to understand better and leverage data for medical advancements and patient care.
The primary challenge in biomedical NER lies in the technical nature of the language used in medical documents, including complex terms and the necessity for specific domain knowledge. Traditional approaches, while robust, often fall short due to the sheer diversity and specificity of biomedical terminology, compounded by the typically sparse data on which these models are trained.
Large language models (LLMs) and machine learning algorithms have traditionally been employed to tackle NER tasks by learning from large datasets. However, these models generally lack the nuanced understanding required to process biomedical texts accurately. They struggle with the specificity of the language and often require extensive, domain-specific datasets that are not always available, leading to suboptimal performance in real-world applications.
Researchers from Northeastern University and Allen Institute for AI have developed an innovative method incorporating dynamic definition augmentation into the inference process of LLMs. This method involves the real-time integration of biomedical concept definitions during model inference, significantly enhancing the model’s ability to recognize and classify biomedical entities correctly. The model can adjust the predictions based on enhanced contextual understanding by providing definitions of relevant terms as part of the input.
This knowledge-augmented approach has shown significant improvements in model performance. For instance, definition augmentation has led to an average increase of 15% in the F1 scores across various tested datasets. More specifically, in some datasets, the performance gains from definition augmentation were as high as 32.6% for Llama 2 and 33.9% for GPT-4, showcasing substantial enhancements over the baseline models. These results underline the effectiveness of integrating precise, contextually relevant knowledge into the NER process.
The success of this approach is further evidenced by its ability to outperform traditional fine-tuning methods, where models are extensively trained on a limited set of domain-specific examples. In contrast, the definition-augmented method requires fewer training instances and less manual annotation, reducing both the time and cost associated with model training. The method’s utility was confirmed across multiple experiments, consistently demonstrating superior accuracy in identifying complex biomedical entities compared to existing techniques.
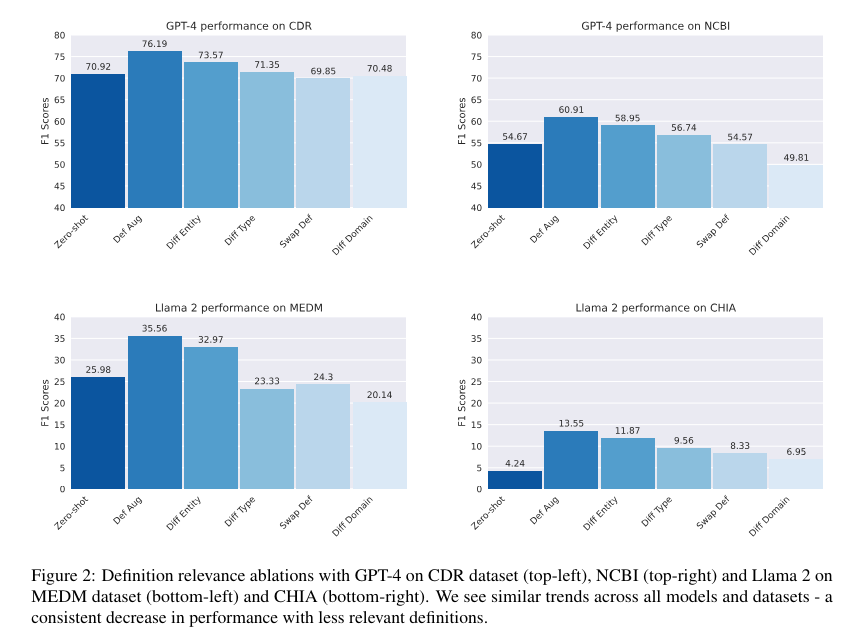
In conclusion, incorporating dynamic definition augmentation into the NER process significantly advances biomedical text analysis. This method improves the accuracy of entity recognition and minimizes the need for extensive specialized datasets, which are often difficult to compile in the biomedical field. The improved performance of LLMs, as evidenced by higher F1 scores and enhanced precision in entity extraction, suggests that this approach could be a valuable tool for medical research and practice. The results of this study not only highlight the potential of knowledge-augmented methodologies but also suggest avenues for future research, including expanding this approach to other specialized domains and languages, potentially broadening its applicability and impact.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post Enhancing Biomedical Named Entity Recognition with Dynamic Definition Augmentation: A Novel AI Approach to Improve Large Language Model Accuracy appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]