


The vulnerability of AI systems, particularly large language models (LLMs) and multimodal models, to adversarial attacks can lead to harmful outputs. These models are designed to assist and provide helpful responses, but adversaries can manipulate them to produce undesirable or even dangerous outputs. The attacks exploit inherent weaknesses in the models, raising concerns about their safety and reliability. Existing defenses, such as refusal training and adversarial training, have significant limitations, often compromising model performance without effectively preventing harmful outputs.
Current methods to improve AI model alignment and robustness include refusal training and adversarial training. Refusal training teaches models to reject harmful prompts, but sophisticated adversarial attacks often bypass these safeguards. Adversarial training involves exposing models to adversarial examples during training to improve robustness, but this method tends to fail against new, unseen attacks and can degrade the model’s performance.
To address these shortcomings, a team of researchers from Black Swan AI, Carnegie Mellon University, and Center for AI Safety proposes a novel method that involves short-circuiting. Inspired by representation engineering, this approach directly manipulates the internal representations responsible for generating harmful outputs. Instead of focusing on specific attacks or outputs, short-circuiting interrupts the harmful generation process by rerouting the model’s internal states to neutral or refusal states. This method is designed to be attack-agnostic and does not require additional training or fine-tuning, making it more efficient and broadly applicable.
The core of the short-circuiting method is a technique called Representation Rerouting (RR). This technique intervenes in the model’s internal processes, particularly the representations that contribute to harmful outputs. By modifying these internal representations, the method prevents the model from completing harmful actions, even under strong adversarial pressure.
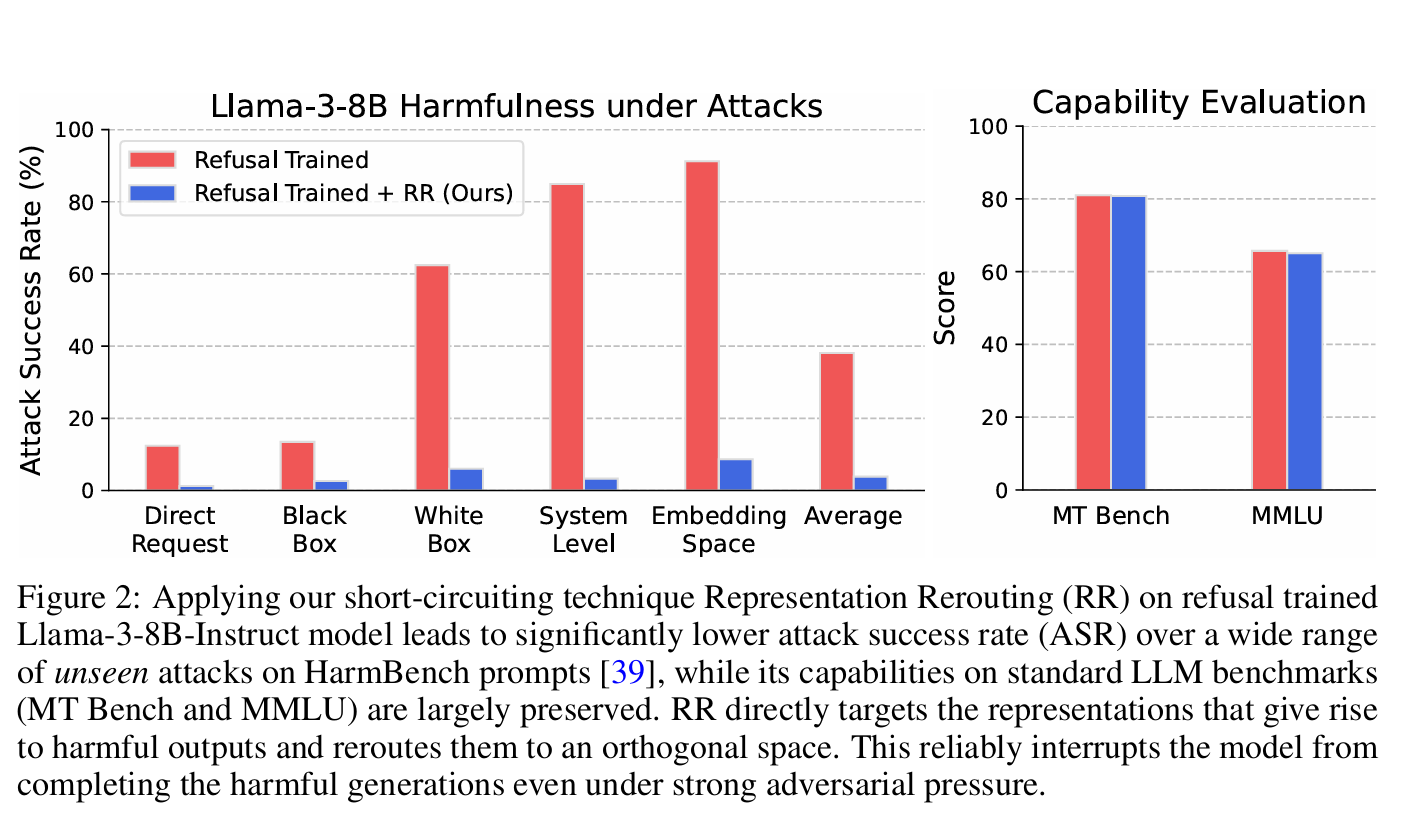
Experimentally, RR was applied to a refusal-trained Llama-3-8B-Instruct model. The results showed a significant reduction in the success rate of adversarial attacks across various benchmarks without sacrificing performance on standard tasks. For instance, the short-circuited model demonstrated lower attack success rates on HarmBench prompts while maintaining high scores on capability benchmarks like MT Bench and MMLU. Additionally, the method proved effective in multimodal settings, improving robustness against image-based attacks and ensuring the model’s harmlessness without impacting its utility.
The short-circuiting method operates by using datasets and loss functions tailored to the task. The training data is divided into two sets: the Short Circuit Set and the Retain Set. The Short Circuit Set contains data that triggers harmful outputs, and the Retain Set includes data that represents safe or desired outputs. The loss functions are designed to adjust the model’s representations to redirect harmful processes to incoherent or refusal states, effectively short-circuiting the harmful outputs.
The problem of AI systems producing harmful outputs due to adversarial attacks is a significant concern. Existing methods like refusal training and adversarial training have limitations that the proposed short-circuiting method aims to overcome. By directly manipulating internal representations, short-circuiting offers a robust, attack-agnostic solution that maintains model performance while significantly enhancing safety and reliability. This approach represents a promising advancement in the development of safer AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
No LLM is secure! A year ago, we unveiled the first of many automated jailbreak capable of cracking all major LLMs.
But there is hope?!
We introduce Short Circuiting: the first alignment technique that is adversarially robust.
Paper: https://t.co/hY7koqrLyl pic.twitter.com/GKWLLv0fox
— Andy Zou (@andyzou_jiaming) June 8, 2024


The post Enhancing AI Safety and Reliability through Short-Circuiting Techniques appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]