

Learning a language can open up new opportunities in a person’s life. It can help people connect with those from different cultures, travel the world, and advance their career. English alone is estimated to have 1.5 billion learners worldwide. Yet proficiency in a new language is difficult to achieve, and many learners cite a lack of opportunity to practice speaking actively and receiving actionable feedback as a barrier to learning.
We are excited to announce a new feature of Google Search that helps people practice speaking and improve their language skills. Within the next few days, Android users in Argentina, Colombia, India (Hindi), Indonesia, Mexico, and Venezuela can get even more language support from Google through interactive speaking practice in English — expanding to more countries and languages in the future. Google Search is already a valuable tool for language learners, providing translations, definitions, and other resources to improve vocabulary. Now, learners translating to or from English on their Android phones will find a new English speaking practice experience with personalized feedback.
 |
| A new feature of Google Search allows learners to practice speaking words in context. |
Learners are presented with real-life prompts and then form their own spoken answers using a provided vocabulary word. They engage in practice sessions of 3-5 minutes, getting personalized feedback and the option to sign up for daily reminders to keep practicing. With only a smartphone and some quality time, learners can practice at their own pace, anytime, anywhere.
Activities with personalized feedback, to supplement existing learning tools
Designed to be used alongside other learning services and resources, like personal tutoring, mobile apps, and classes, the new speaking practice feature on Google Search is another tool to assist learners on their journey.
We have partnered with linguists, teachers, and ESL/EFL pedagogical experts to create a speaking practice experience that is effective and motivating. Learners practice vocabulary in authentic contexts, and material is repeated over dynamic intervals to increase retention — approaches that are known to be effective in helping learners become confident speakers. As one partner of ours shared:
“Speaking in a given context is a skill that language learners often lack the opportunity to practice. Therefore this tool is very useful to complement classes and other resources.” – Judit Kormos, Professor, Lancaster University
We are also excited to be working with several language learning partners to surface content they are helping create and to connect them with learners around the world. We look forward to expanding this program further and working with any interested partner.
Personalized real-time feedback
Every learner is different, so delivering personalized feedback in real time is a key part of effective practice. Responses are analyzed to provide helpful, real-time suggestions and corrections.
The system gives semantic feedback, indicating whether their response was relevant to the question and may be understood by a conversation partner. Grammar feedback provides insights into possible grammatical improvements, and a set of example answers at varying levels of language complexity give concrete suggestions for alternative ways to respond in this context.
 |
| The feedback is composed of three elements: Semantic analysis, grammar correction, and example answers. |
Contextual translation
Among the several new technologies we developed, contextual translation provides the ability to translate individual words and phrases in context. During practice sessions, learners can tap on any word they don’t understand to see the translation of that word considering its context.
 |
| Example of contextual translation feature. |
This is a difficult technical task, since individual words in isolation often have multiple alternative meanings, and multiple words can form clusters of meaning that need to be translated in unison. Our novel approach translates the entire sentence, then estimates how the words in the original and the translated text relate to each other. This is commonly known as the word alignment problem.
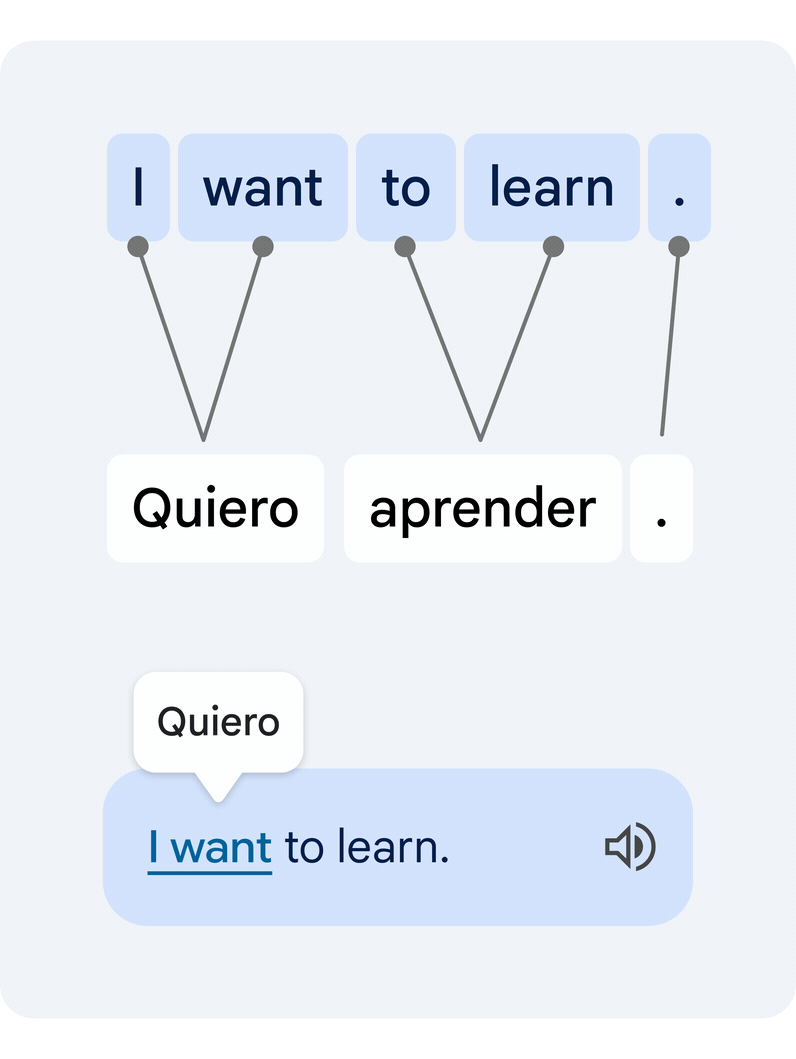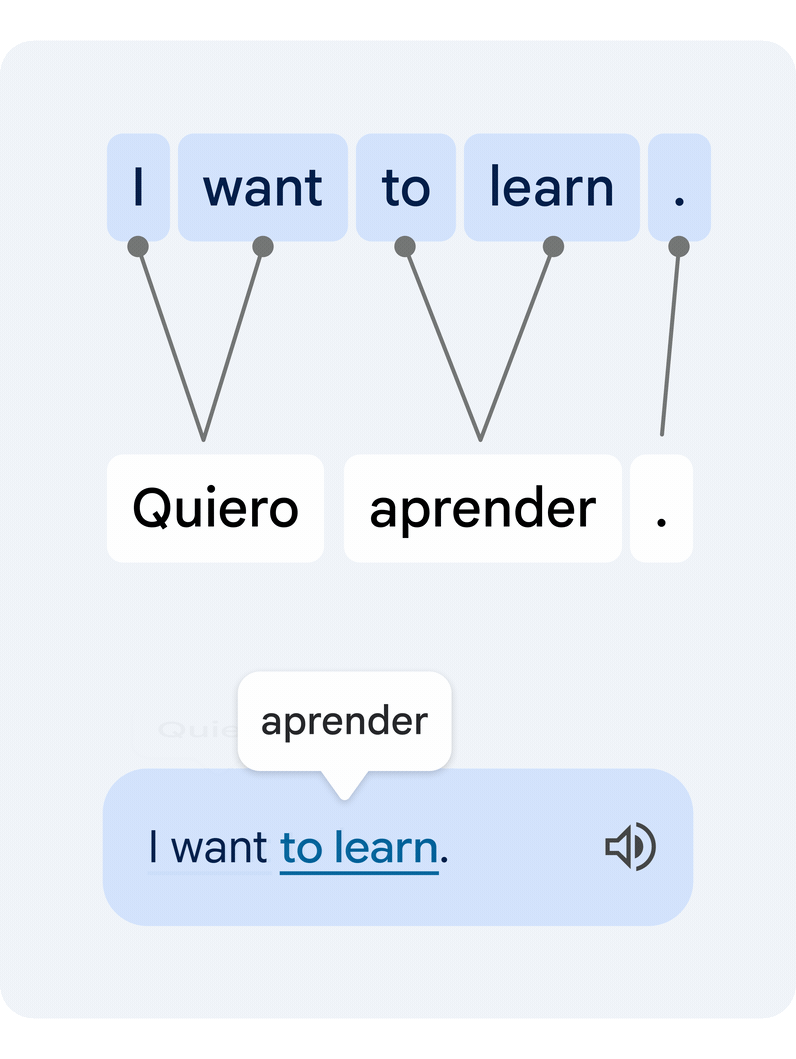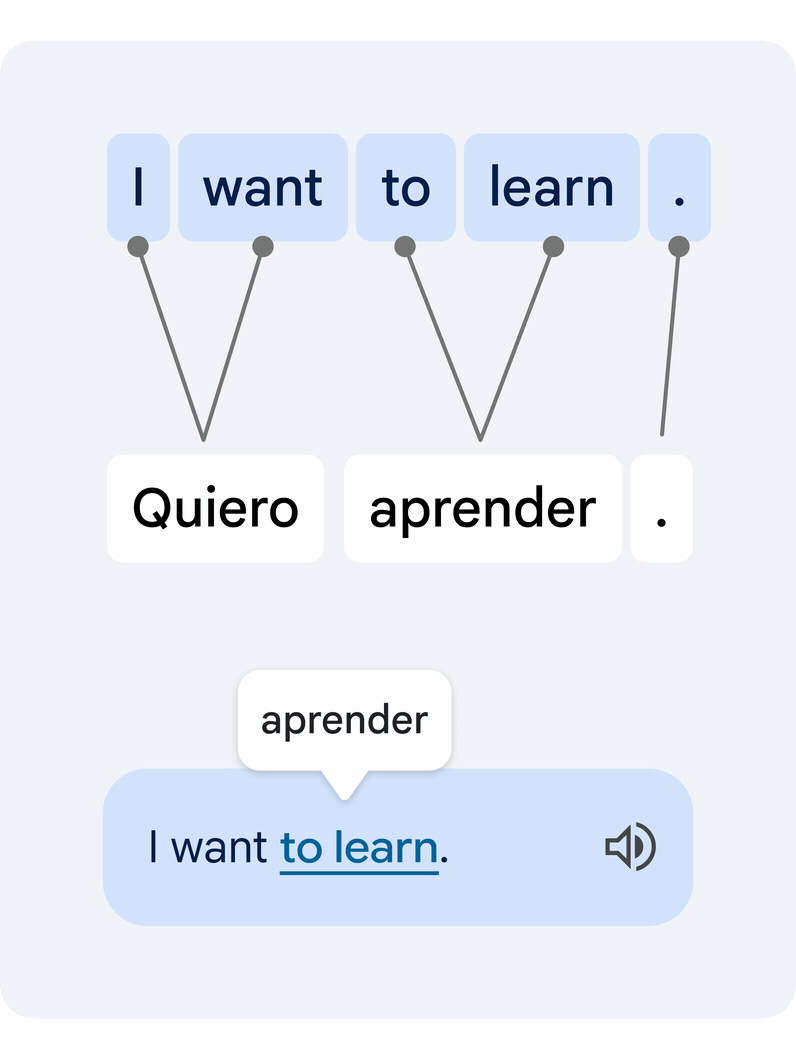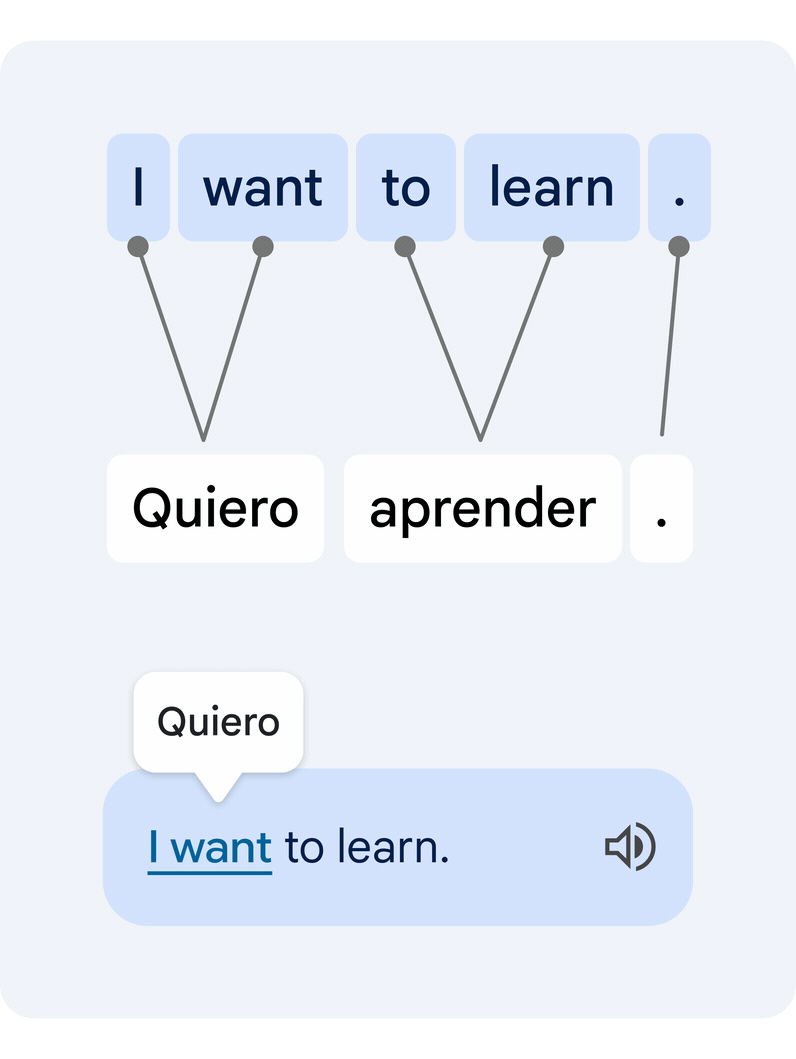 |
| Example of a translated sentence pair and its word alignment. A deep learning alignment model connects the different words that create the meaning to suggest a translation. |
The key technology piece that enables this functionality is a novel deep learning model developed in collaboration with the Google Translate team, called Deep Aligner. The basic idea is to take a multilingual language model trained on hundreds of languages, then fine-tune a novel alignment model on a set of word alignment examples (see the figure above for an example) provided by human experts, for several language pairs. From this, the single model can then accurately align any language pair, reaching state-of-the-art alignment error rate (AER, a metric to measure the quality of word alignments, where lower is better). This single new model has led to dramatic improvements in alignment quality across all tested language pairs, reducing average AER from 25% to 5% compared to alignment approaches based on Hidden Markov models (HMMs).
 |
| Alignment error rates (lower is better) between English (EN) and other languages. |
This model is also incorporated into Google’s translation APIs, greatly improving, for example, the formatting of translated PDFs and websites in Chrome, the translation of YouTube captions, and enhancing Google Cloud’s translation API.
Grammar feedback
To enable grammar feedback for accented spoken language, our research teams adapted grammar correction models for written text (see the blog and paper) to work on automatic speech recognition (ASR) transcriptions, specifically for the case of accented speech. The key step was fine-tuning the written text model on a corpus of human and ASR transcripts of accented speech, with expert-provided grammar corrections. Furthermore, inspired by previous work, the teams developed a novel edit-based output representation that leverages the high overlap between the inputs and outputs that is particularly well-suited for short input sentences common in language learning settings.
The edit representation can be explained using an example:
- Input: I1 am2 so3 bad4 cooking5
- Correction: I1 am2 so3 bad4 at5 cooking6
- Edits: ( at , 4, PREPOSITION, 4)
In the above, “at” is the word that is inserted at position 4 and “PREPOSITION” denotes this is an error involving prepositions. We used the error tag to select tag-dependent acceptance thresholds that improved the model further. The model increased the recall of grammar problems from 4.6% to 35%.
Some example output from our model and a model trained on written corpora:
| Example 1 | Example 2 | |||
| User input (transcribed speech) | I live of my profession. | I need a efficient card and reliable. | ||
| Text-based grammar model | I live by my profession. | I need an efficient card and a reliable. | ||
| New speech-optimized model | I live off my profession. | I need an efficient and reliable card. |
Semantic analysis
A primary goal of conversation is to communicate one’s intent clearly. Thus, we designed a feature that visually communicates to the learner whether their response was relevant to the context and would be understood by a partner. This is a difficult technical problem, since early language learners’ spoken responses can be syntactically unconventional. We had to carefully balance this technology to focus on the clarity of intent rather than correctness of syntax.
Our system utilizes a combination of two approaches:
- Sensibility classification: Large language models like LaMDA or PaLM are designed to give natural responses in a conversation, so it’s no surprise that they do well on the reverse: judging whether a given response is contextually sensible.
- Similarity to good responses: We used an encoder architecture to compare the learner’s input to a set of known good responses in a semantic embedding space. This comparison provides another useful signal on semantic relevance, further improving the quality of feedback and suggestions we provide.
 |
| The system provides feedback about whether the response was relevant to the prompt, and would be understood by a communication partner. |
ML-assisted content development
Our available practice activities present a mix of human-expert created content, and content that was created with AI assistance and human review. This includes speaking prompts, focus words, as well as sets of example answers that showcase meaningful and contextual responses.
 |
| A list of example answers is provided when the learner receives feedback and when they tap the help button. |
Since learners have different levels of ability, the language complexity of the content has to be adjusted appropriately. Prior work on language complexity estimation focuses on text of paragraph length or longer, which differs significantly from the type of responses that our system processes. Thus, we developed novel models that can estimate the complexity of a single sentence, phrase, or even individual words. This is challenging because even a phrase composed of simple words can be hard for a language learner (e.g., “Let s cut to the chase”). Our best model is based on BERT and achieves complexity predictions closest to human expert consensus. The model was pre-trained using a large set of LLM-labeled examples, and then fine-tuned using a human expert–labeled dataset.
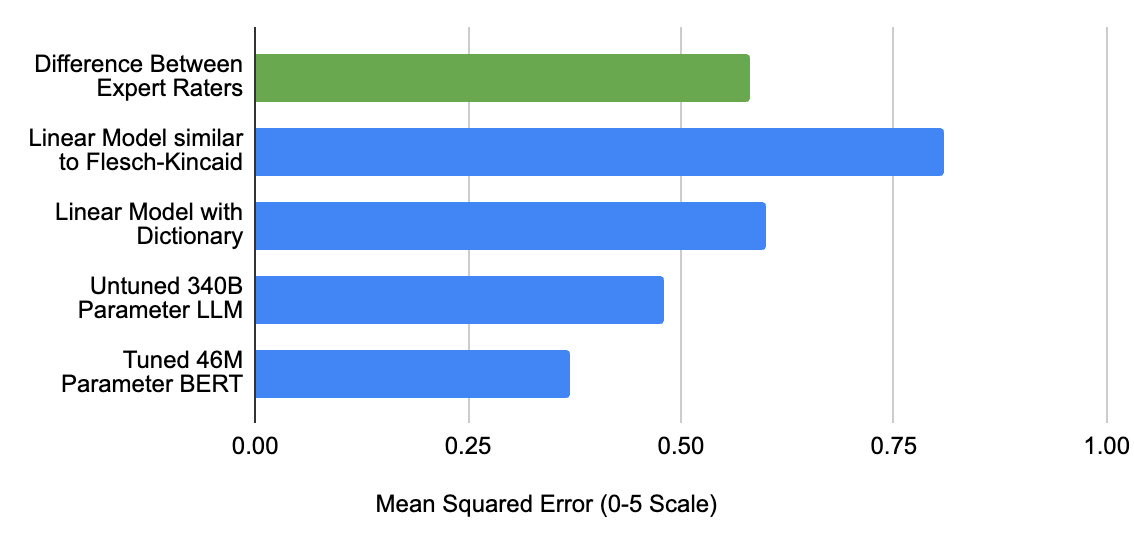 |
| Mean squared error of various approaches’ performance estimating content difficulty on a diverse corpus of ~450 conversational passages (text / transcriptions). Top row: Human raters labeled the items on a scale from 0.0 to 5.0, roughly aligned to the CEFR scale (from A1 to C2). Bottom four rows: Different models performed the same task, and we show the difference to the human expert consensus. |
Using this model, we can evaluate the difficulty of text items, offer a diverse range of suggestions, and most importantly challenge learners appropriately for their ability levels. For example, using our model to label examples, we can fine-tune our system to generate speaking prompts at various language complexity levels.
| Vocabulary focus words, to be elicited by the questions | ||||||
| guitar | apple | lion | ||||
| Simple | What do you like to play? | Do you like fruit? | Do you like big cats? | |||
| Intermediate | Do you play any musical instruments? | What is your favorite fruit? | What is your favorite animal? | |||
| Complex | What stringed instrument do you enjoy playing? | Which type of fruit do you enjoy eating for its crunchy texture and sweet flavor? | Do you enjoy watching large, powerful predators? | |||
Furthermore, content difficulty estimation is used to gradually increase the task difficulty over time, adapting to the learner’s progress.
Conclusion
With these latest updates, which will roll out over the next few days, Google Search has become even more helpful. If you are an Android user in India (Hindi), Indonesia, Argentina, Colombia, Mexico, or Venezuela, give it a try by translating to or from English with Google.
We look forward to expanding to more countries and languages in the future, and to start offering partner practice content soon.
Acknowledgements
Many people were involved in the development of this project. Among many others, we thank our external advisers in the language learning field: Jeffrey Davitz, Judit Kormos, Deborah Healey, Anita Bowles, Susan Gaer, Andrea Revesz, Bradley Opatz, and Anne Mcquade.
#Education #Search #Speech [Source: Google AI]