


Despite their expanding capabilities, large language models (LLMs) need help with processing extensive contexts. These limitations stem from Transformer-based architectures struggling to extrapolate beyond their training window size. Processing long token sequences requires substantial computational resources and risks producing noisy attention embeddings. These constraints hinder LLMs’ ability to incorporate domain-specific, private, or up-to-date information effectively. Researchers have attempted various approaches, including retrieval-based methods, but a significant performance gap remains between short- and long-context tasks, even when employing existing long-context architectures.
Researchers have explored various approaches to extend LLMs’ context windows, focusing on improving softmax attention, reducing computational costs, and enhancing positional encodings. Retrieval-based methods, particularly group-based k-NN retrieval, have shown promise by retrieving large token groups and functioning as hierarchical attention.
Concurrently, research in neural models of episodic memory has provided insights into brain processes for storing experiences. These models highlight the importance of surprise-based event segmentation and temporal dynamics in memory formation and retrieval. Studies reveal that transformer-based LLMs exhibit temporal contiguity and asymmetry effects similar to human memory retrieval, suggesting potential for functioning as episodic memory retrieval models with appropriate context information.
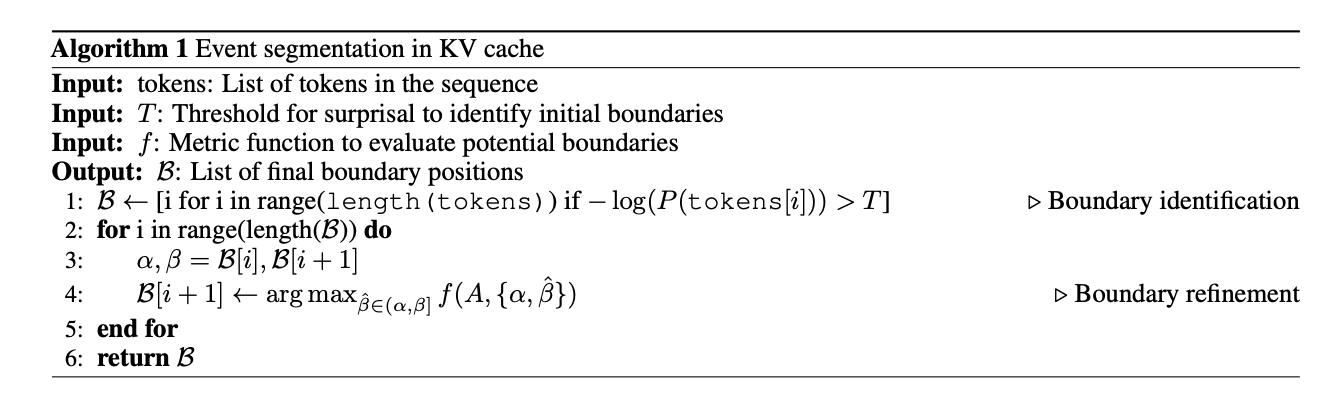
Researchers from Huawei Noah’s Ark Lab and University College London propose a EM-LLM, a unique architecture integrating episodic memory into Transformer-based LLMs, enabling them to handle significantly longer contexts. It divides the context into initial tokens, evicted tokens (managed by an episodic memory model), and local context. The architecture forms memories by segmenting token sequences into events based on surprise levels during inference, refining boundaries using graph-theoretic metrics to optimize cohesion and separation. Memory retrieval employs a two-stage mechanism: k-NN search retrieves similar events, while a contiguity buffer maintains temporal context. This approach mimics human episodic memory, enhancing the model’s ability to process extended contexts and perform complex temporal reasoning tasks efficiently.
EM-LLM extends pre-trained LLMs to handle larger context lengths. It divides the context into initial tokens, evicted tokens, and local context. The local context uses full softmax attention, representing the most recent and relevant information. Evicted tokens, managed by a memory model similar to short-term episodic memory, comprise the majority of past tokens. Initial tokens act as attention sinks. For retrieved tokens outside the local context, EM-LLM assigns fixed position embeddings. This architecture allows EM-LLM to process information beyond its pre-trained context window while maintaining performance characteristics.
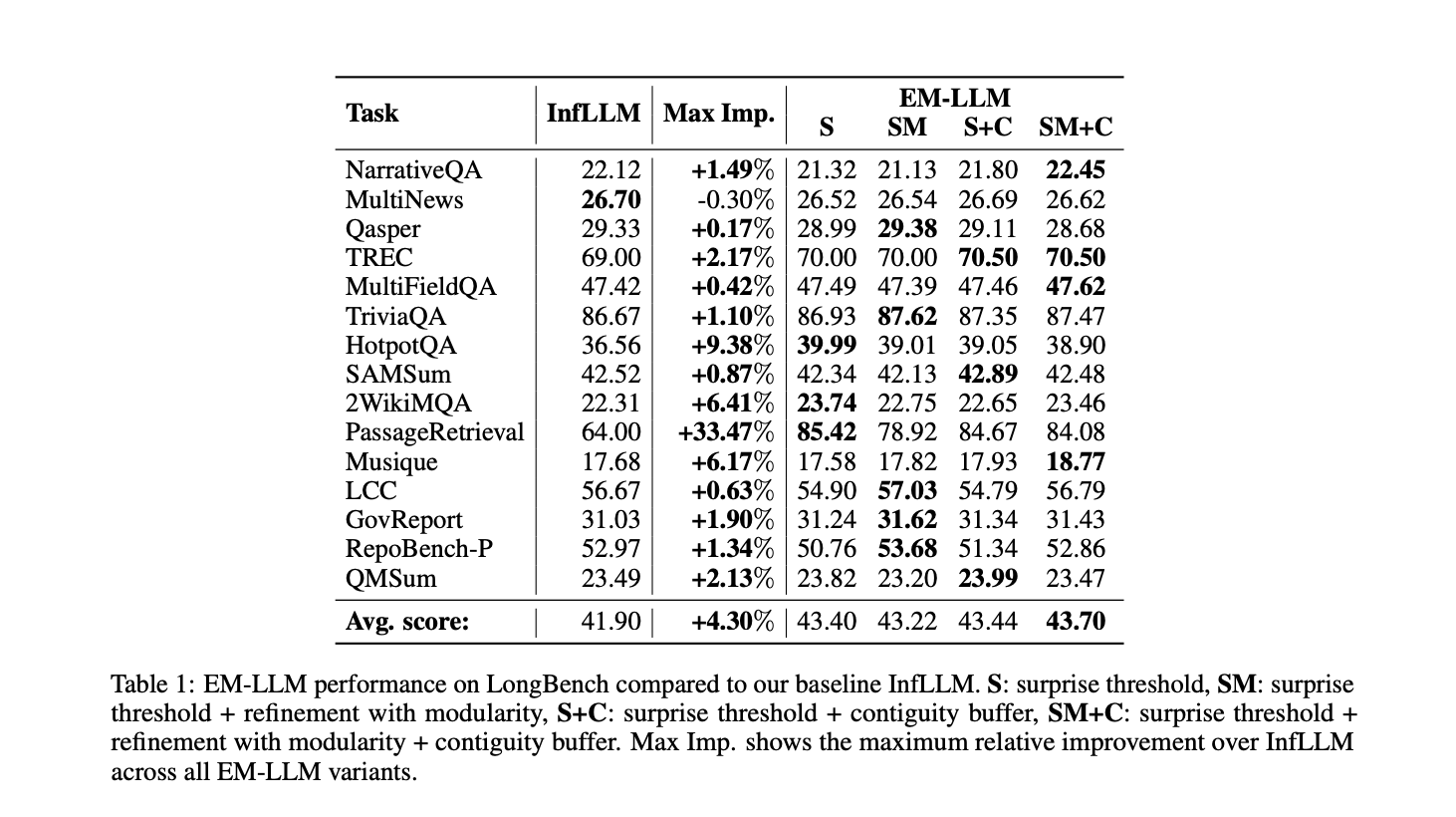
EM-LLM demonstrated improved performance on long-context tasks compared to the baseline InfLLM model. On the LongBench dataset, EM-LLM surpassed InfLLM in all but one task, achieving an overall increase of 1.8 percentage points (4.3% relative improvement). Also, EM-LLM showed significant gains on the PassageRetrieval task, with up to a 33% improvement, and a 9.38% improvement on the HotpotQA task. These results highlight EM-LLM’s enhanced ability to recall detailed information from large contexts and perform complex reasoning over multiple supporting documents. The study also found that surprise-based segmentation methods closely aligned with human event perception, outperforming fixed or random event segmentation approaches.
EM-LLM represents a significant advancement in language models with extended context-processing capabilities. By integrating human episodic memory and event cognition into transformer-based LLMs, it effectively processes information from vastly extended contexts without pre-training. The combination of surprise-based event segmentation, graph-theoretic boundary refinement, and two-stage memory retrieval enables superior performance on long-context tasks. EM-LLM offers a path towards virtually infinite context windows, potentially revolutionizing LLM interactions with continuous, personalized exchanges. This flexible framework serves as an alternative to traditional RAG techniques and provides a scalable computational model for testing human memory hypotheses. By bridging cognitive science and machine learning, EM-LLM not only enhances LLM performance but also inspires further research at the intersection of LLMs and human memory mechanisms.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post EM-LLM: A Novel and Flexible Architecture that Integrates Key Aspects of Human Episodic Memory and Event Cognition into Transformer-based Language Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]