


As LLMs become increasingly integral to various AI tasks, their massive parameter sizes lead to high memory requirements and bandwidth consumption. While quantization-aware training (QAT) offers a potential solution by allowing models to operate with lower-bit representations, existing methods often require extensive training resources, making them impractical for large models. The research paper addresses the challenge of managing the significant memory requirements of large language models (LLMs) in natural language processing and artificial intelligence.
Current quantization techniques for LLMs include post-training quantization (PTQ) and quantized parameter-efficient fine-tuning (Q-PEFT). PTQ minimizes memory usage during inference by converting pre-trained model weights to low-bit formats, but it can compromise accuracy, especially in low-bit regimes. Q-PEFT methods, like QLoRA, allow for fine-tuning on consumer-grade GPUs but require reverting to higher-bit formats for additional tuning, necessitating another round of PTQ, which can degrade performance.
The researchers propose Efficient Quantization-Aware Training (EfficientQAT) to address these limitations. The EfficientQAT framework operates through its two main phases. In the Block-AP phase, quantization-aware training is performed on all parameters within each transformer block, utilizing block-wise reconstruction to maintain efficiency. This approach circumvents the need for full model training, thus preserving memory resources. Following this, the E2E-QP phase fixes the quantized weights and trains only the quantization parameters (step sizes), which enhances the model’s efficiency and performance without the overhead associated with training the entire model. This dual-phase strategy improves convergence speed and allows for effective instruction tuning of quantized models.
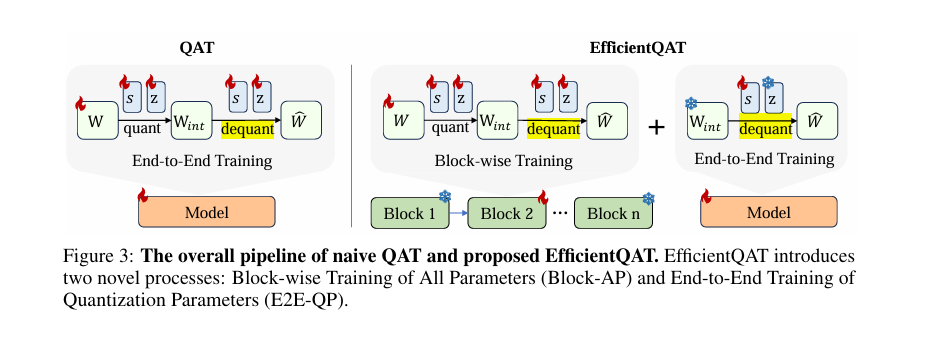
The Block-AP phase of EfficientQAT begins with a standard uniform quantization method, quantizing and then dequantizing weights in a block-wise manner. Inspired by BRECQ and OmniQuant, this method allows for efficient training with less data and memory compared to traditional end-to-end QAT approaches. By training all parameters, including scaling factors and zero points, Block-AP ensures precise calibration and avoids the overfitting issues typically associated with training the entire model simultaneously.
In the E2E-QP phase, only the quantization parameters are trained end-to-end while keeping the quantized weights fixed. This phase leverages the robust initialization provided by Block-AP, allowing for efficient and accurate tuning of the quantized model for specific tasks. E2E-QP enables instruction tuning of quantized models, ensuring memory efficiency as the trainable parameters constitute only a small fraction of the total network.
EfficientQAT demonstrates significant improvements over previous quantization methods. For instance, it achieves a 2-bit quantization of a Llama-2-70B model on a single A100-80GB GPU in just 41 hours, with less than 3% accuracy degradation compared to the full-precision model. Additionally, it outperforms existing Q-PEFT methods in low-bit scenarios, providing a more hardware-efficient solution.
The EfficientQAT framework presents a compelling solution to the challenges posed by large language models in terms of memory and computational efficiency. By introducing a two-phase training approach focusing on block-wise training and end-to-end quantization parameter optimization, the researchers effectively reduce the resource demands of quantization-aware training while maintaining high performance. This method represents a significant advancement in the field of model quantization, providing a practical pathway for deploying large language models in resource-constrained environments.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Efficient Quantization-Aware Training (EfficientQAT): A Novel Machine Learning Quantization Technique for Compressing LLMs appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]