


Scaling Transformer-based models to over 100 billion parameters has led to groundbreaking results in natural language processing. These large language models excel in various applications, but deploying them efficiently poses challenges due to the sequential nature of generative inference, where each token’s computation relies on the preceding tokens. This necessitates meticulous parallel layouts and memory optimizations. The study highlights crucial engineering principles for efficiently serving large-scale Transformer models in diverse production settings, ensuring scalability and low-latency inference.
Google researchers investigate efficient generative inference for large Transformer models, focusing on tight latency targets and long sequence lengths. They developed an analytical model to optimize multi-dimensional partitioning techniques for TPU v4 slices and implemented low-level optimizations. This achieved superior latency and Model FLOPS Utilization (MFU) tradeoffs for 500B+ parameter models, outperforming FasterTransformer benchmarks. Using multi-query attention, they scaled context lengths up to 32× larger. Their PaLM 540B model attained 29ms latency per token with int8 quantization and a 76% MFU, supporting a 2048-token context length, highlighting practical applications in chatbots and high-throughput offline inference.
Prior works on efficient partitioning for training large models include NeMo Megatron, GSPMD, and Alpa, which utilize tensor and pipeline parallelism with memory optimizations. FasterTransformer sets benchmarks for multi-GPU multi-node inference, while DeepSpeed Inference uses ZeRO offload to leverage CPU and NVMe memory. EffectiveTransformer reduces padding by packing sequences. Unlike these, this study develops partitioning strategies based on analytical tradeoffs. For improving inference efficiency, approaches include efficient attention layers, distillation, pruning, and quantization. The study incorporates model quantization for inference speedups and suggests its techniques could complement other compression methods.
Scaling model sizes improves capabilities but increases latency, throughput, and MFU inference costs. Key metrics include latency (prefill and decode times), throughput (tokens processed/generated per second), and MFU (observed vs. theoretical throughput). Larger models face memory and compute challenges, with small batch sizes dominated by weight loading times and larger ones by KV cache. Efficient inference requires balancing low latency and high throughput through strategies like 1D/2D weight-stationary and weight-gathered partitioning. Attention mechanisms impact memory use, with multi-query attention reducing KV cache size but adding communication costs.
In a study of PaLM models, techniques like multi-query attention and parallel attention/feedforward layers were evaluated using JAX and XLA on TPU v4 chips. For the PaLM 540B model, padding attention heads enhanced partitioning efficiency. Different partitioning strategies were tested: 1D and 2D weight-stationary layouts and weight-gathered layouts, with 2D performing better at higher chip counts. Multi-query attention allowed larger context lengths with less memory use than multihead. The study demonstrated that optimizing partitioning layouts based on batch size and phase (prefill vs. generation) is crucial for balancing efficiency and latency.
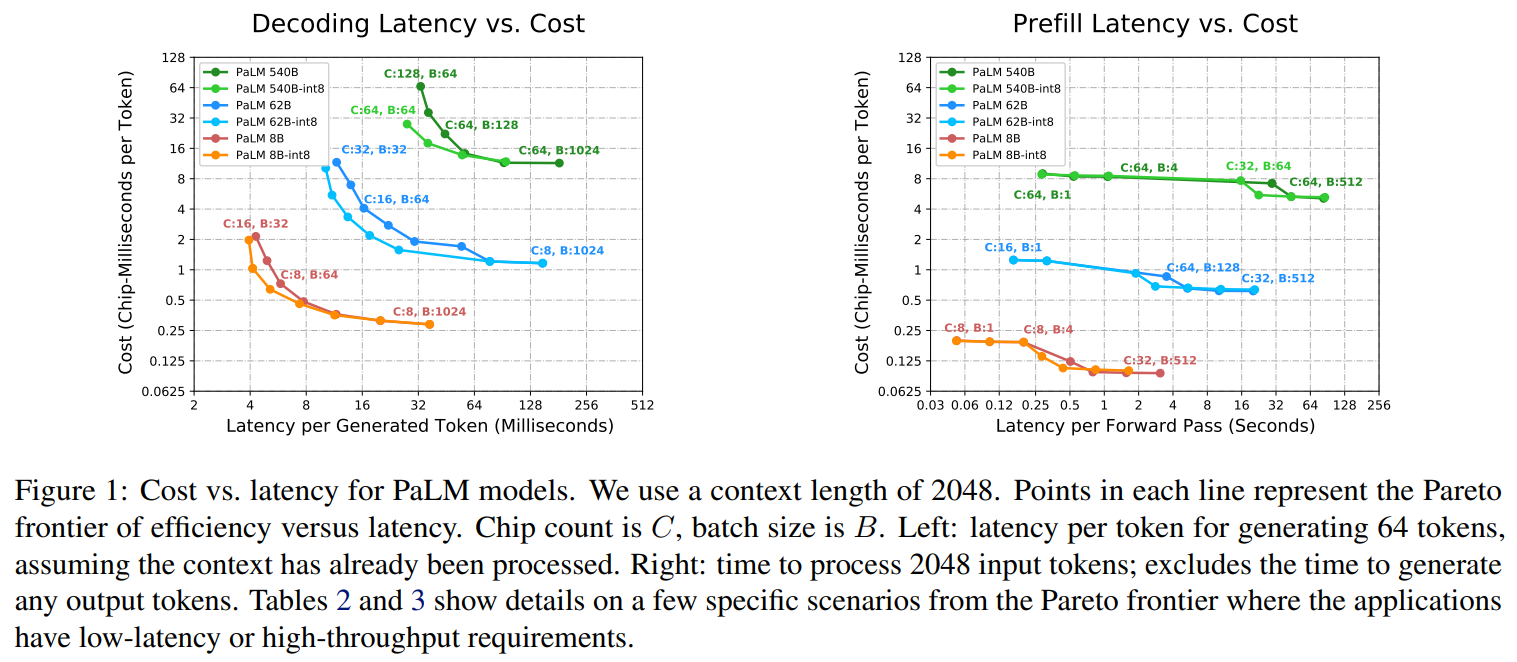
Large Transformer models are revolutionizing various domains, but democratizing their access requires significant advancements. This study explores scaling Transformer inference workloads and suggests practical partitioning methods to meet stringent latency demands, especially for 500B+ parameter models. Optimal latencies were achieved by scaling inference across 64+ chips. Multiquery attention with effective partitioning reduces memory costs for long-context inference. Although scaling improves performance, FLOP count and communication volume remain limiting factors. Techniques like sparse architectures and adaptive computation, which reduce FLOPs per token and chip-to-chip communication, promise further cost and latency improvements.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Efficient Deployment of Large-Scale Transformer Models: Strategies for Scalable and Low-Latency Inference appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]