


In recent years, LLMs have transitioned from research tools to practical applications, largely due to their increased scale during training. However, as most of their computational resources are consumed during inference, efficient pretraining and inference are crucial. Post-training techniques like quantization, Low-Rank Adapters (LoRA), and pruning offer ways to reduce memory usage and inference time. Combining these methods can further enhance efficiency. QLoRA, for example, introduced innovations allowing for 4-bit quantization and LoRA finetuning to be used together, demonstrating the potential for leveraging multiple efficiency techniques simultaneously.
Researchers from Meta FAIR, UMD, Cisco, Zyphra, MIT, and Sequoia Capital examine a layer-pruning approach for popular open-weight pretrained LLMs. They find minimal performance degradation occurs on question-answering benchmarks until a significant fraction (up to half) of the layers are removed. Their method involves identifying optimal layers for pruning based on similarity across layers and then performing a small amount of finetuning using parameter-efficient finetuning (PEFT) methods like quantization and Low-Rank Adapters (QLoRA). This approach significantly reduces computational resources for finetuning while improving inference memory and latency. The study suggests that current pretraining methods may not effectively utilize deeper layers.
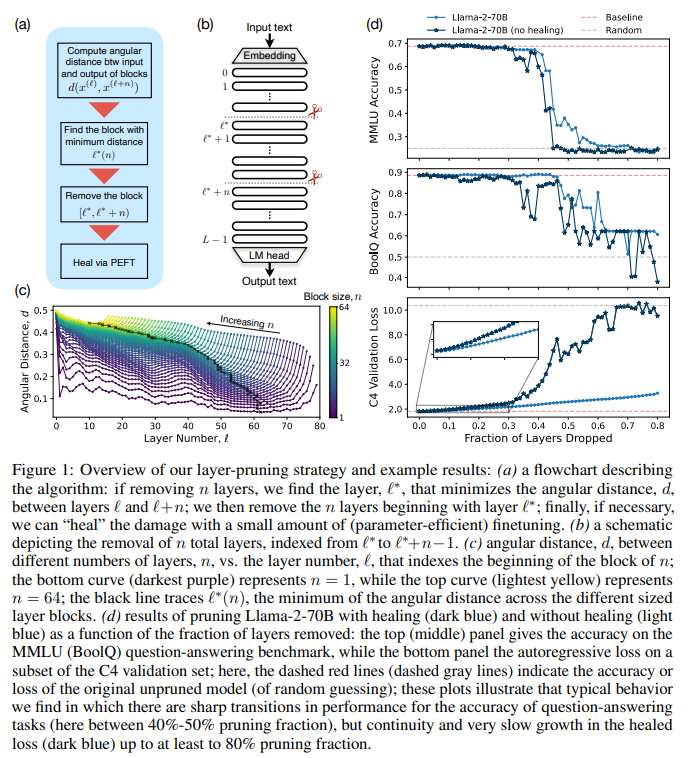
Pruning, a technique for reducing the size of trained machine-learning models, involves removing unnecessary parameters. Early methods focused on individual parameter removal, leading to irregular sparsification patterns. Structured pruning emerged to remove parameter groups, enhancing practicality. Recent efforts extend pruning to transformer models, exploring various elimination approaches. While BERT-style models often drop final layers, GPT-style models exhibit nuanced behavior. Model distillation offers an alternative size reduction method. Parameter-efficient finetuning methods like LoRA and QLoRA complement pruning. Deep studies on LLM properties corroborate the findings, highlighting the potential for layer pruning while underscoring layer-dependent knowledge storage.
The intuition behind layer pruning is based on the idea that in a residual network, the representations gradually change from layer to layer. Pruning aims to remove certain layers while minimizing the network’s overall functionality disruption. The algorithm for layer pruning involves selecting several layers to prune, computing the angular distance between the input and output of these layers, dropping the layers that minimize this distance, and optionally fine-tuning the pruned model to mitigate any performance degradation. Another simpler strategy involves removing the deepest layers and fine-tuning the model to restore performance. This process is crucial for maintaining model efficiency while minimizing information loss.
A simpler pruning strategy involves removing the deepest layers of a model, excluding the final layer, followed by a healing process through fine-tuning. This method eliminates the need to load or infer the unpruned model onto a GPU. Despite its simplicity, it provides meaningful insights into the importance of optimizing the layer to prune. Experimentally, this strategy shows rapid decay in performance without healing, with accuracy dropping to near-random levels on question-answering benchmarks and rapid increases in loss on next-token prediction. However, after healing, the performance of this simpler strategy becomes comparable to the principal similarity-informed pruning strategy, indicating that post-pruning fine-tuning primarily aims to mitigate damage rather than acquire additional knowledge.
In conclusion, the LLaMA family has made machine learning more accessible, resulting in innovations such as LoRA and quantization that have improved efficiency. Researchers have also contributed by developing a simple layer-pruning technique. For instance, the Llama-2-70B model can be compressed to 17.5 GB of memory using 4-bit quantization and a 50% layer-pruning fraction. This reduces the number of FLOPs required per token, making running and fine-tuning large models on consumer GPUs efficiently easier. Future research can focus on enhancing pruning and healing methods, understanding the differences in phase transitions between loss and QA accuracies, and investigating how pretraining affects pruning effectiveness and where knowledge is stored within model layers.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post Efficiency Breakthroughs in LLMs: Combining Quantization, LoRA, and Pruning for Scaled-down Inference and Pre-training appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]