


Jailbreak attacks are vital for uncovering and addressing security flaws in LLMs, as they aim to bypass protective measures and produce prohibited outputs. However, the absence of a standardized framework for implementing these attacks hampers thorough security assessments, given the diverse array of methods available. Despite the remarkable progress of LLMs in natural language processing, they remain susceptible to jailbreak attempts. The proliferation of new jailbreak techniques underscores the need for robust defense strategies. Yet, comparing these attacks proves challenging due to variations in evaluation criteria and the absence of readily available source code, exacerbating efforts to identify and counter LLM vulnerabilities.
Researchers from the School of Computer Science, Fudan University, Shanghai, China, Institute of Modern Languages and Linguistics, Fudan University, Shanghai, China, and Shanghai AI Laboratory have developed EasyJailbreak, a comprehensive framework simplifying the creation and assessment of jailbreak attacks against LLMs. EasyJailbreak employs four key components: Selector, Mutator, Constraint, and Evaluator, allowing for modular construction of attacks. With support for various LLMs, including GPT-4, it enables standardized benchmarking, flexibility in attack development, and compatibility with diverse models. Security evaluations conducted on 10 LLMs reveal a concerning 60% average breach probability, emphasizing the critical need for improved security measures in LLMs.

Researchers investigating LLM security vulnerabilities have explored various jailbreak attack methodologies, categorized into Human-Design, Long-tail Encoding, and Prompt Optimization. Human design involves manually crafting prompts to exploit model weaknesses, such as role-playing or scenario crafting. Long-tail Encoding leverages rare data formats to bypass security checks, while Prompt Optimization automates the identification of vulnerabilities through techniques like gradient-based exploration or genetic algorithms. Examples include GCG, AutoDAN, GPTFUZZER, FuzzLLM, and PAIR, which iteratively refine prompts or employ persuasive language to manipulate LLMs.
EasyJailbreak is a unified framework designed to conduct jailbreak attacks on LLMs easily. It integrates 11 classic attack methods into a user-friendly interface, allowing for straightforward execution with minimal code. Before launching an attack, users must specify queries, seeds, and models. The framework consists of four key components: Selector, Mutator, Constraint, and Evaluator, each serving a specific role in refining and evaluating jailbreak attempts. EasyJailbreak generates comprehensive reports post-attack, offering insights into success rates, response perplexity, and detailed information on malicious queries to enhance model defenses.
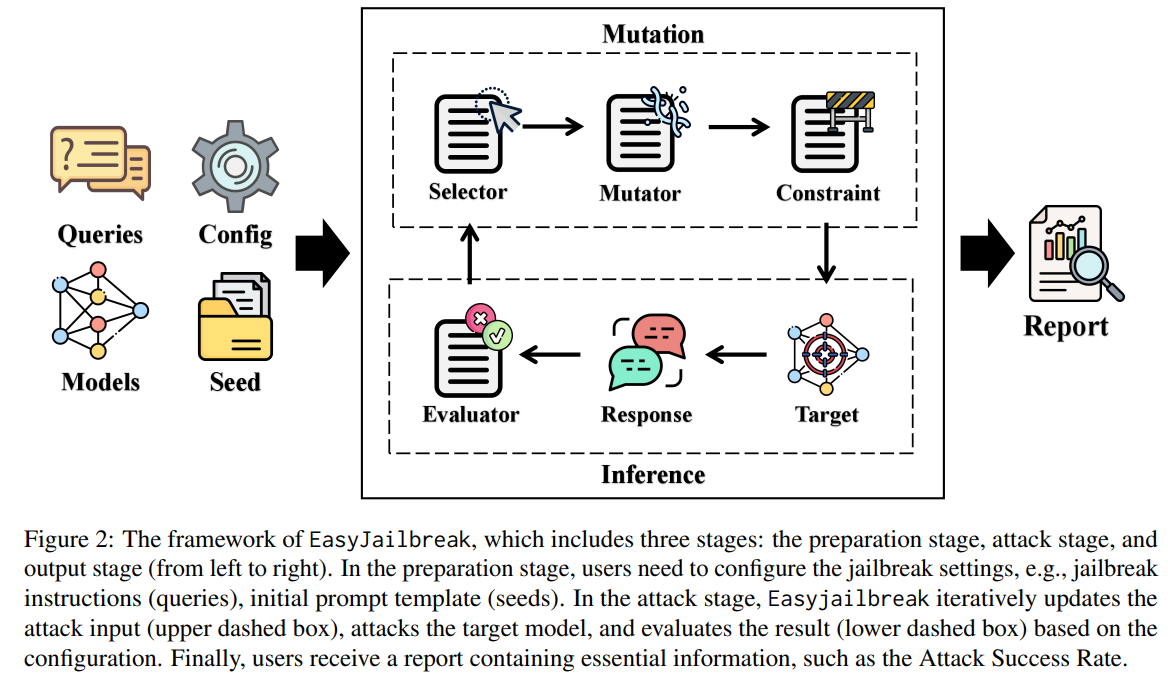
EasyJailbreak streamlines the creation and assessment of jailbreak attacks on LLMs by offering a modular framework comprising selector, mutant, constraint, and evaluator components. With support for 11 distinct jailbreak methods, it aids in validating the security of various LLMs, revealing a notable vulnerability with a 60% average breach probability. Advanced models like GPT-3.5-Turbo and GPT-4 display susceptibility with average Attack Success Rates (ASR) of 57% and 33%, respectively. This framework equips researchers with essential tools to enhance LLM security and fosters innovation in safeguarding against emerging threats.
In conclusion, EasyJailbreak marks a significant advancement in securing LLMs against evolving jailbreak threats, offering a unified, modular framework for evaluating and developing attack and defense strategies across various models. The evaluation underscores the critical need for improved security measures, revealing a 60% average breach probability in advanced LLMs. The study emphasizes responsible research and deployment, advocating for ethical usage and responsible disclosure to mitigate risks of misuse. EasyJailbreak fosters collaboration in the cybersecurity community, aiming to create more resilient LLMs through vigilant monitoring, iterative updates, and a long-term commitment to uncovering and addressing vulnerabilities for societal benefit.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post EasyJailbreak: A Unified Machine Learning Framework for Enhancing LLM Security by Simplifying Jailbreak Attack Creation and Assessment Against Emerging Threats appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #Technology [Source: AI Techpark]