


Most LMMs integrate vision and language by converting images into visual tokens fed as sequences into LLMs. While effective for multimodal understanding, this method significantly increases memory and computation demands, especially with high-resolution photos or videos. Various techniques, like spatial grouping and token compression, aim to reduce the number of visual tokens but often compromise on detailed visual information. Despite these efforts, the fundamental approach remains the same: visual tokens are transformed into a 1D sequence and input into LLMs, inherently increasing processing overhead.
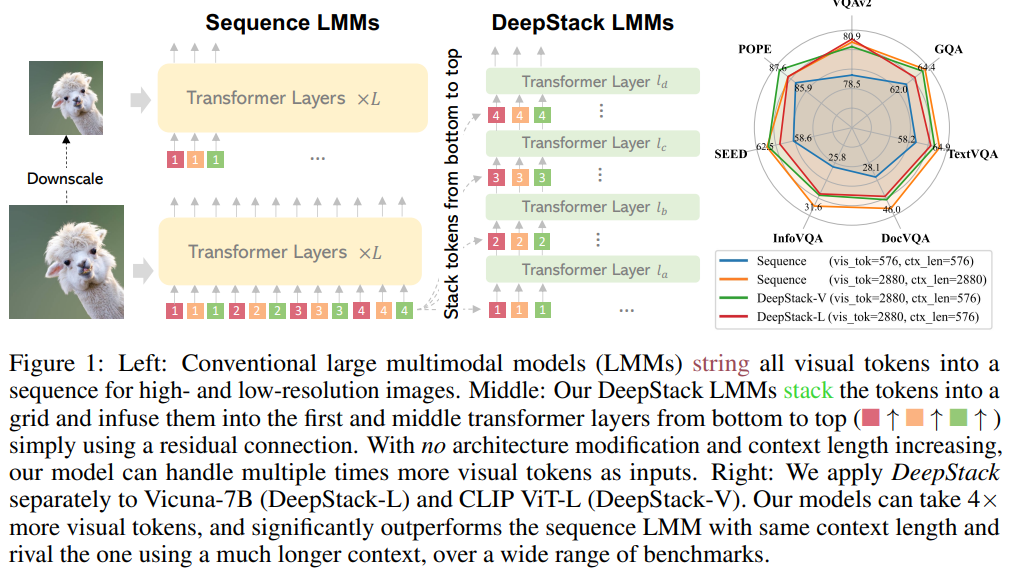
Researchers from Fudan University and Microsoft have developed “DeepStack,” a new architecture for LMMs. Instead of feeding a long sequence of visual tokens into the language model’s first layer, DeepStack distributes these tokens across multiple layers, aligning each group with a corresponding layer. This bottom-to-top approach enhances the model’s ability to process complex visual inputs without increasing computational costs. After testing the LLaVA-1.5 and LLaVA-Next models, DeepStack shows significant performance gains across various benchmarks, particularly in high-resolution tasks, and can handle more tokens efficiently than traditional methods.
Recent advancements in LLMs like BERT, T5, and GPT have revolutionized natural language processing (NLP) using transformers and pretraining-then-finetuning strategies. These models excel in various tasks, from text generation to question answering. Simultaneously, LMMs like CLIP and Flamingo effectively integrate vision and language by aligning them in a shared semantic space. However, handling high-resolution images and complex visual inputs remains challenging due to high computational costs. The new “DeepStack” approach addresses this by distributing visual tokens across multiple LLMs or Vision Transformers (ViTs) layers, enhancing performance and reducing overhead.
DeepStack enhances LMMs using a dual-stream approach to incorporate fine-grained visual details without increasing context length. It divides image processing into a global view stream for overall information and a high-resolution stream that adds detailed image features across LLM layers. High-resolution tokens are upsampled and dilated, then fed into different LLM layers. This strategy significantly improves the model’s ability to handle complex visual inputs efficiently. Unlike traditional methods that concatenate visual tokens, DeepStack integrates them across layers, maintaining efficiency and enhancing the model’s visual processing capabilities.
The experiments on DeepStack demonstrate its efficacy in enhancing multi-modal language models by integrating high-resolution visual tokens. Utilizing a two-stage training process, it leverages the CLIP image encoder to mosaic high-res image patches into whole-image features. During pre-training, the model uses 558k samples from LAION and other datasets, while fine-tuning incorporates 748k samples, adapting LLaVA’s pipeline. DeepStack consistently outperforms baselines like LLaVA on various VQA and multi-modal benchmarks, proving its capability to handle detailed visual information. It excels in text-oriented and zero-shot video QA tasks, confirming that early and strategic layer insertion of visual tokens significantly enhances model performance without extra computational cost.
In conclusion, DeepStack introduces an innovative approach to enhancing LMMs by stacking visual tokens across multiple model layers rather than feeding them all into the first layer. This method reduces computational and memory demands while significantly improving performance on high-resolution tasks. By distributing visual tokens across different layers of the transformer, DeepStack enables more effective interactions between these tokens across layers. This results in substantial gains, outperforming traditional models like LLaVA on various benchmarks. The technique proves particularly advantageous in tasks demanding detailed visual comprehension, paving the way for more efficient and powerful multimodal models.
Check out the Paper, GitHub, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post DeepStack: Enhancing Multimodal Models with Layered Visual Token Integration for Superior High-Resolution Performance appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]