


Natural language processing is advancing rapidly, focusing on optimizing large language models (LLMs) for specific tasks. These models, often containing billions of parameters, pose a significant challenge in customization. The aim is to develop efficient and better methods for fine-tuning these models to specific downstream tasks without prohibitive computational costs. This requires innovative approaches to parameter-efficient fine-tuning (PEFT) that maximize performance while minimizing resource usage.
One major problem in this domain is the resource-intensive nature of customizing LLMs for specific tasks. Traditional fine-tuning methods typically update all model parameters, which can lead to high computational costs and overfitting. Given the scale of modern LLMs, such as those with sparse architectures that distribute tasks across multiple specialized experts, there is a pressing need for more efficient fine-tuning techniques. The challenge lies in optimizing performance while ensuring the computational burden remains manageable.
Existing methods for PEFT in dense-architecture LLMs include low-rank adaptation (LoRA) and P-Tuning. These methods generally involve adding new parameters to the model or selectively updating existing ones. For instance, LoRA decomposes weight matrices into low-rank components, which helps reduce the number of parameters that need to be trained. However, these approaches have primarily focused on dense models and do not fully exploit the potential of sparse-architecture LLMs. In sparse models, different tasks activate different subsets of parameters, making traditional methods less effective.
DeepSeek AI and Northwestern University researchers have introduced a novel method called Expert-Specialized Fine-Tuning (ESFT) tailored for sparse-architecture LLMs, specifically those using a mixture-of-experts (MoE) architecture. This method aims to fine-tune only the most relevant experts for a given task while freezing the other experts and model components. By doing so, ESFT enhances tuning efficiency and maintains the specialization of the experts, which is crucial for optimal performance. The ESFT method capitalizes on the MoE architecture’s inherent ability to assign different tasks to experts, ensuring that only the necessary parameters are updated.
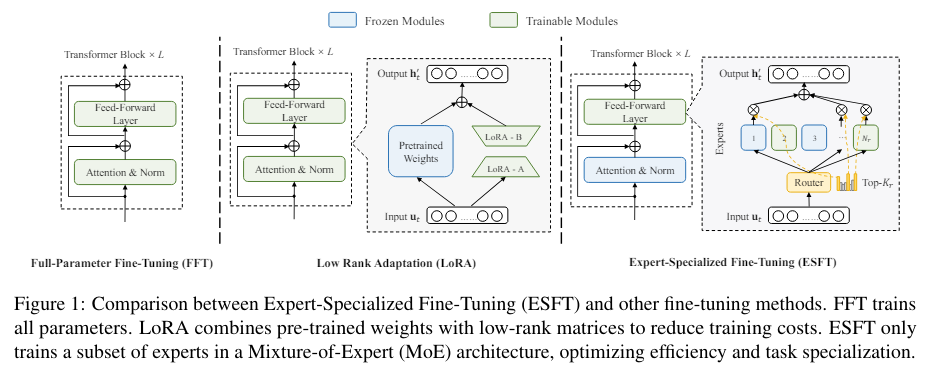
In more detail, ESFT involves calculating the affinity scores of experts to task-specific data and selecting a subset of experts with the highest relevance. These selected experts are then fine-tuned while the rest of the model remains unchanged. This selective approach significantly reduces the computational costs associated with fine-tuning. For instance, ESFT can reduce storage requirements by up to 90% and training time by up to 30% compared to full-parameter fine-tuning. This efficiency is achieved without compromising the model’s overall performance, as demonstrated by the experimental results.
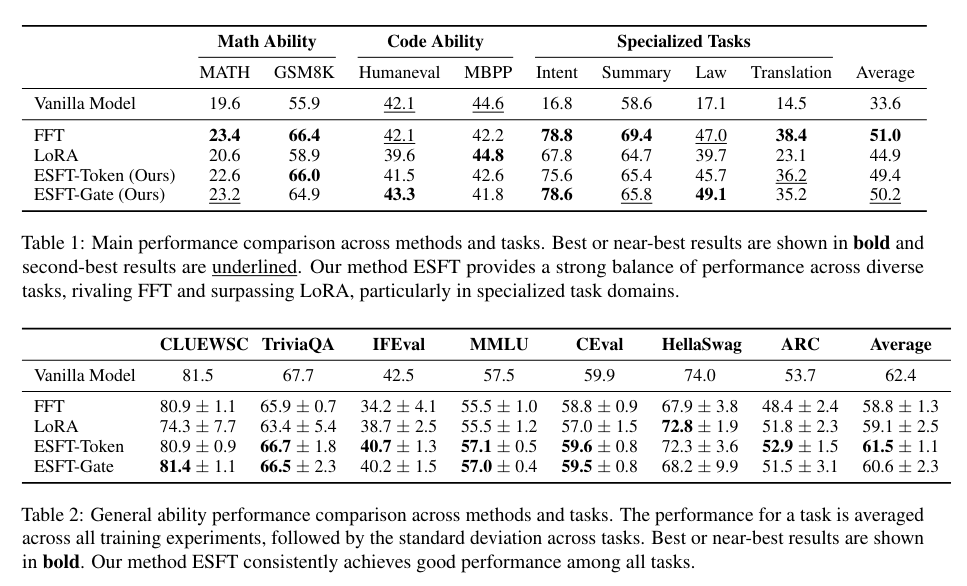
In various downstream tasks, ESFT not only matched but often surpassed the performance of traditional full-parameter fine-tuning methods. For example, in tasks like math and code, ESFT achieved significant performance gains while maintaining a high degree of specialization. The method’s ability to efficiently fine-tune a subset of experts, selected based on their relevance to the task, highlights its effectiveness. The results showed that ESFT maintained general task performance better than other PEFT methods like LoRA, making it a versatile and powerful tool for LLM customization.

In conclusion, the research introduces Expert-Specialized Fine-Tuning (ESFT) as a solution to the problem of resource-intensive fine-tuning in large language models. By selectively tuning relevant experts, ESFT optimizes both performance and efficiency. This method leverages the specialized architecture of sparse-architecture LLMs to achieve superior results with reduced computational costs. The research demonstrates that ESFT can significantly improve training efficiency, reduce storage and training time, and maintain high performance across various tasks. This makes ESFT a promising approach for future developments in customizing large language models.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post DeepSeek AI Researchers Propose Expert-Specialized Fine-Tuning, or ESFT to Reduce Memory by up to 90% and Time by up to 30% appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]