


Data curation is essential for developing high-quality training datasets for language models. This process includes techniques such as deduplication, filtering, and data mixing, which enhance the efficiency and accuracy of models. The goal is to create datasets that improve the performance of models across various tasks, from natural language understanding to complex reasoning.
A significant challenge in training language models is the need for standardized benchmarks for data curation strategies. This makes it difficult to discern whether improvements in model performance are due to better data curation or other factors, such as model architecture or hyperparameters. This ambiguity hinders the optimization of training datasets effectively, making it challenging for researchers to develop more accurate and efficient models.
Existing methods for data curation include deduplication, filtering, and using model-based approaches to assemble training sets. These methods are applied to large datasets to reduce redundancy and enhance quality. However, the performance of these strategies varies significantly, and there needs to be a consensus on the most effective approach for curating training data for language models. The need for clearer, standardized benchmarks further complicates this process, making it difficult to compare the effectiveness of different data curation methods.
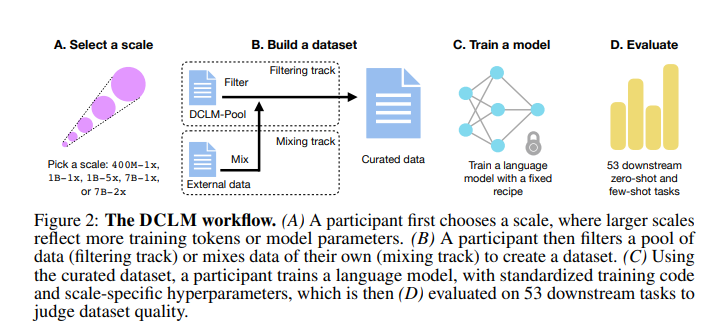
A team of researchers from various reputed institutes including the University of Washington, Apple, and the Toyota Research Institute have introduced a novel data curation workflow called DataComp for Language Models (DCLM). This method aims to create high-quality training datasets and establish a benchmark for evaluating dataset performance. This interdisciplinary approach combines expertise from various fields to tackle the complex issue of data curation for language models.
The DCLM workflow involves several critical steps. Initially, text is extracted from raw HTML using Resiliparse, a highly efficient text extraction tool. Deduplication is performed using a Bloom filter to remove redundant data, which helps improve data diversity and reduces memorization in models. This is followed by model-based filtering, which employs a fastText classifier trained on high-quality data from sources like OpenWebText2 and ELI5. These steps are crucial for creating a high-quality training dataset known as DCLM-BASELINE. The meticulous process ensures that only the most relevant and high-quality data is included in the training set.
The DCLM-BASELINE dataset demonstrated significant improvements in model performance. When used to train a 7B parameter language model with 2.6 trillion training tokens, the resulting model achieved a 64% 5-shot accuracy on MMLU. This represents a substantial enhancement over previous models and highlights the effectiveness of the DCLM method in producing high-quality training datasets. The research team compared their results with state-of-the-art models, such as GPT-4 and Llama 3, demonstrating that the DCLM-BASELINE model performs competitively, even with reduced computational resources.
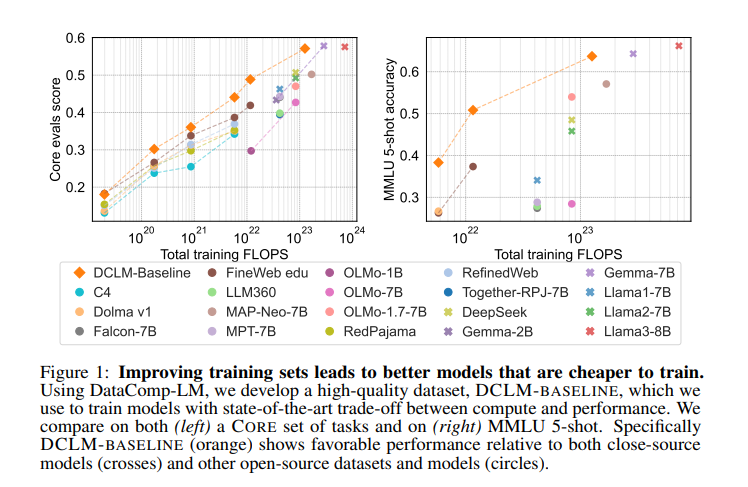
The proposed DCLM workflow sets a new benchmark for data curation in language models. It provides a comprehensive framework for evaluating and improving training datasets, which is essential for advancing the field of language modeling. The research team encourages further exploration of data curation strategies to build more effective and efficient language models. They highlight the potential for future research to expand on their findings, exploring different data sources, filtering methods, and model architectures to continue improving the quality of training datasets.
In conclusion, the DCLM workflow, a product of a collaborative effort by institutions like the University of Washington, Apple, and the Toyota Research Institute, offers a robust solution to improve dataset quality and model performance. This approach sets a new benchmark for future research in data curation and language model development. The collaborative nature of this research underscores the importance of interdisciplinary approaches in addressing complex research problems. This innovative workflow not only advances the current state of language modeling but also paves the way for future improvements in the field.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post DataComp for Language Models (DCLM): An AI Benchmark for Language Model Training Data Curation appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]