


In artificial intelligence, integrating multimodal inputs for video reasoning stands as a frontier, challenging yet ripe with potential. Researchers increasingly focus on leveraging diverse data types – from visual frames and audio snippets to more complex 3D point clouds – to enrich AI’s understanding and interpretation of the world. This endeavor aims to mimic human sensory integration and surpass it in depth and breadth, enabling machines to make sense of complex environments and scenarios with unprecedented clarity.
At the heart of this challenge is the problem of efficiently and effectively fusing these varied modalities. Traditional approaches have often fallen short, either by needing to be more flexible in accommodating new data types or necessitating prohibitive computational resources. Thus, the quest is for a solution that not only embraces the diversity of sensory data but does so with agility and scalability.
Current methodologies in multimodal learning have shown promise but are hampered by their computational intensity and inflexibility. These systems typically require substantial parameter updates or dedicated modules for each new modality, making the integration of new data types cumbersome and resource-intensive. Such limitations hinder the adaptability and scalability of AI systems in dealing with the richness of real-world inputs.
A groundbreaking framework proposed by UNC-Chapel Hill researchers was designed to revolutionize how AI systems handle multimodal inputs for video reasoning. This innovative approach introduces a modular, efficient system for fusing different modalities, such as optical flow, 3D point clouds, and audio, without requiring extensive parameter updates or bespoke modules for each data type. At its core, CREMA utilizes a query transformer architecture that integrates diverse sensory data, paving the way for a more nuanced and comprehensive AI understanding of complex scenarios.
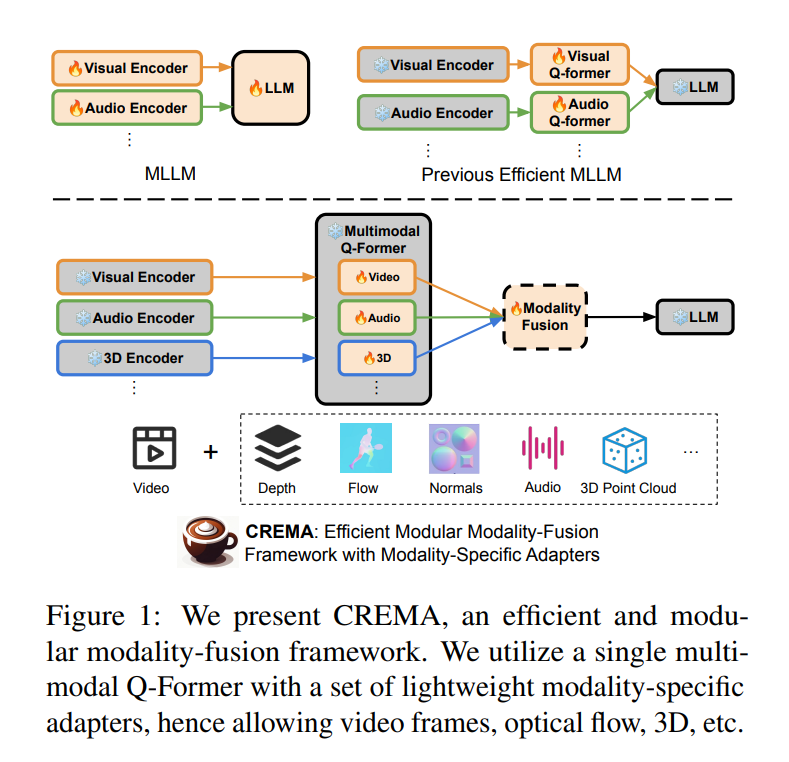
CREMA’s methodology is notable for its efficiency and adaptability. Employing a set of parameter-efficient modules allows the framework to project diverse modality features into a common embedding space, facilitating seamless integration without overhauling the underlying model architecture. This approach conserves computational resources and ensures the model’s future-proofing, ready to accommodate new modalities as they become relevant.
CREMA’s performance has been rigorously validated across various benchmarks, demonstrating superior or equivalent results compared to existing multimodal learning models with a fraction of the trainable parameters. This efficiency does not come at the cost of effectiveness; CREMA adeptly balances the inclusion of new modalities, ensuring that each contributes meaningfully to the reasoning process without overwhelming the system with redundant or irrelevant information.
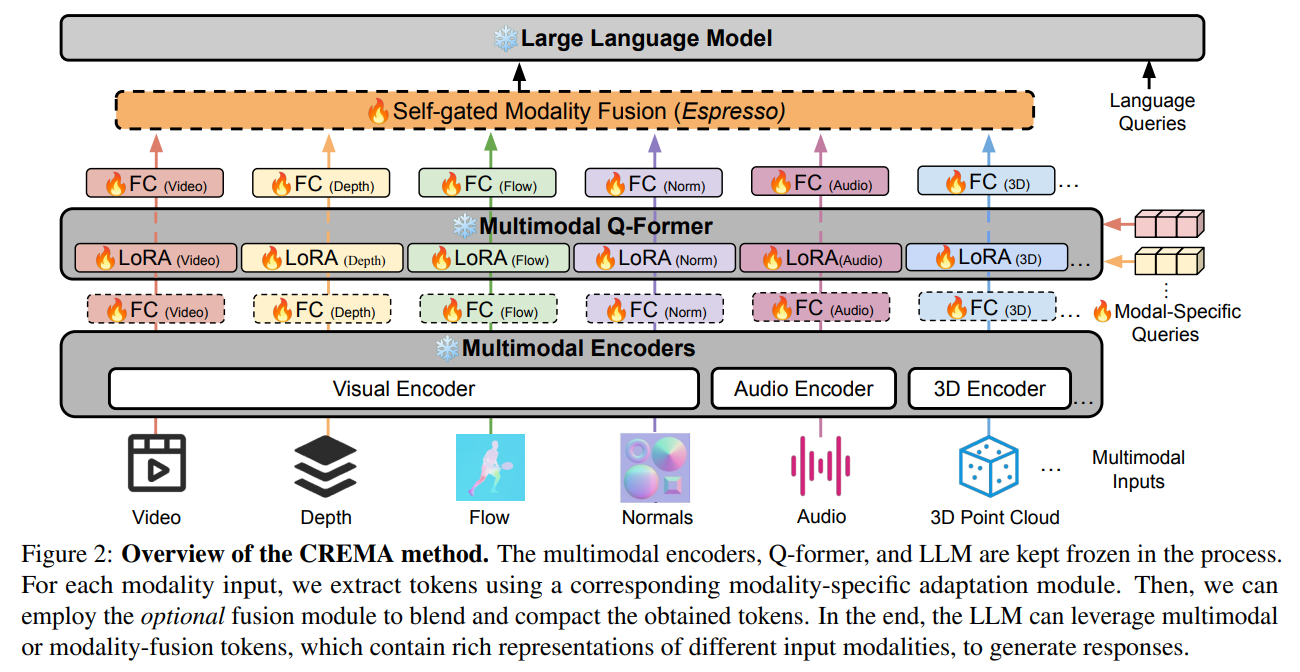
In conclusion, CREMA represents a significant leap forward in multimodal video reasoning. Its innovative fusion of diverse data types into a coherent, efficient framework not only addresses the challenges of flexibility and computational efficiency but also sets a new standard for future developments in the field. The implications of this research are profound, promising to enhance AI’s ability to interpret and interact with the world more nuanced and intelligently.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post CREMA by UNC-Chapel Hill: A Modular AI Framework for Efficient Multimodal Video Reasoning appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]