


Ordered sequences, including text, audio, and code, rely on position information for meaning. Large language models (LLMs), like the Transformer architecture, lack inherent ordering information and treat sequences as sets. Position Encoding (PE) addresses this by assigning an embedding vector to each position, which is crucial for LLMs’ understanding. PE methods, including absolute and relative measures, are integral to LLMs, accommodating various tokenization methods. However, token variability poses challenges for precise position addressing in sequences.
Initially, attention mechanisms didn’t require PE as they were used with RNNs. Memory Network introduced PE alongside attention, employing learnable embedding vectors for relative positions. PE gained traction with the Transformer architecture, where both absolute and relative PE variants were explored. Various modifications followed, such as simplified bias terms, and CoPE, which contextualizes position measurement. Unlike RNNs, CoPE allows parallelization in Transformer training, enhancing efficiency. Some research works favor relative PE in recent LLMs, with RoPE offering a modification-free implementation.
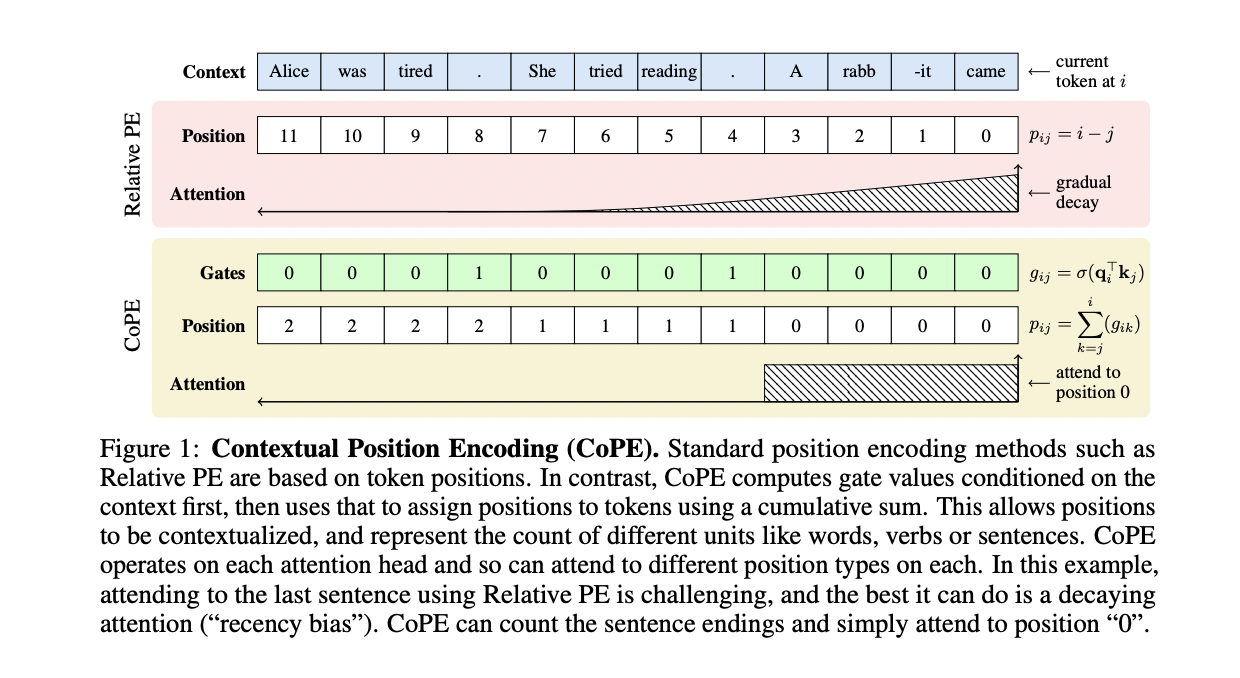
Researchers from Meta present Contextual Position Encoding (CoPE), COPE determines token positions based on their context vectors. By computing gate values for previous tokens using their key vectors relative to the current token, CoPE establishes fractional positional values, requiring interpolation of assigned embeddings for computation. These embeddings enhance the attention operation by incorporating positional information. CoPE excels in toy tasks like counting and selective copying, surpassing token-based PE methods, particularly in out-of-domain scenarios. In language modeling tasks using Wikipedia text and code, CoPE consistently demonstrates superior performance, highlighting its real-world applicability.
In CoPE, position measurement is context-dependent, determined by gate values computed for each query-key pair, allowing differentiation through backpropagation. Position values are computed by aggregating gate values between the current and target tokens. It generalizes relative PE by accommodating various positional concepts, not just token counts. Unlike token positions, CoPE’s values can be fractional, necessitating interpolation between integer embeddings for position embeddings. The effectiveness of CoPE is demonstrated in toy tasks and real-world applications, showcasing its superiority over token-based PE methods. In state-of-the-art LLMs, standard position encodings exhibit failures, especially in tasks requiring precise counting, indicating the need for more advanced position-addressing techniques like CoPE.
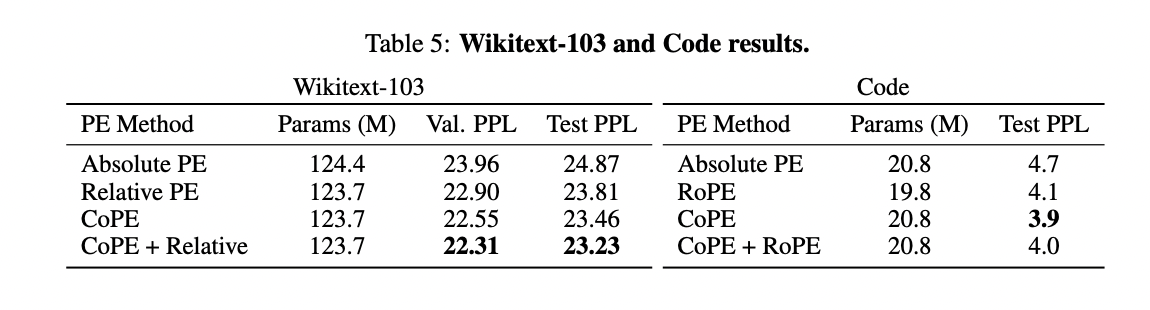
Absolute PE exhibits the poorest performance among the compared PE methods. CoPE surpasses relative PE and shows further enhancement when combined with it, underscoring CoPE’s efficacy in general language modeling tasks. Evaluating CoPE on code data reveals its superiority over Absolute PE and RoPE, with perplexity improvements of 17% and 5%, respectively. While combining RoPE and CoPE embeddings yields improvements over RoPE alone, it does not surpass the performance of CoPE alone. This underscores CoPE’s effectiveness in utilizing context for improved modeling, particularly in structured data domains like code.
The paper introduces CoPE, a robust position encoding method that measures position contextually, diverging from token-based paradigms. This approach offers enhanced flexibility in positional addressing, yielding performance improvements across various tasks in text and code domains. CoPE’s potential extends to domains like video and speech, where token position might be less suitable. Future research could explore training larger models with CoPE and evaluating their performance on downstream tasks to assess its efficacy and applicability further.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Contextual Position Encoding (CoPE): A New Position Encoding Method that Allows Positions to be Conditioned on Context by Incrementing Position only on Certain Tokens Determined by the Model appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]