


The pursuit of high-fidelity 3D representations from sparse images has seen considerable advancements, yet the challenge of accurately determining camera poses remains a significant hurdle. Traditional structure-from-motion methods often falter when faced with limited views, prompting a shift towards learning-based strategies that aim to predict camera poses from a sparse image set. These innovative approaches explore various learning techniques, including regression and denoising diffusion, to enhance pose estimation accuracy. However, a pivotal question arises regarding the optimal representation of camera poses for neural learning. Traditional methods rely on extrinsic camera matrices, comprising a rotation and translation component. However, there might be more effective approaches for learning-based methods that could benefit from more granular, distributed representations.
In this innovative study, researchers propose a paradigm shift in camera parametrization by introducing a patch-wise ray prediction model (shown in Figure 1). This novel approach diverges from the traditional global rotation and translation prediction, opting instead for a model that predicts individual rays for each image patch. This method is well-suited for transformer-based models that process sets of features extracted from these patches, offering a more detailed and nuanced understanding of camera poses.
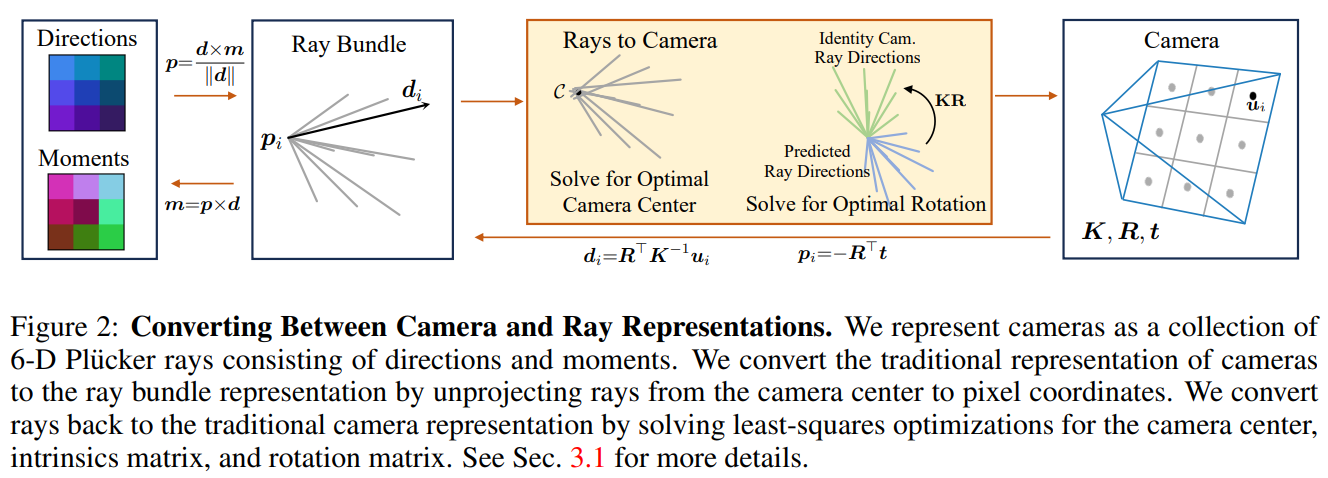
The core of this approach lies in its ability to translate a collection of predicted rays into classical camera extrinsic and intrinsics, a method that also accommodates non-perspective cameras. Initial experiments with a patch-based transformer model already demonstrate a notable improvement over existing state-of-the-art pose prediction methods, showcasing the potential of this distributed ray representation. Furthermore, the incorporation of a denoising diffusion-based probabilistic model to address inherent ambiguities in ray prediction further elevates the model’s performance, enabling it to distinguish between distinct distribution modes effectively.
The effectiveness of this method is rigorously evaluated on the CO3D dataset, examining its performance across both familiar and novel categories and its ability to generalize to completely unseen datasets. This comprehensive analysis confirms the superior performance of this ray diffusion approach in accurately estimating camera poses, especially in challenging sparse-view scenarios.
This research not only introduces a revolutionary camera parametrization method but also sets a new benchmark for pose estimation accuracy. Moving away from global pose representation to a more detailed, ray-based model opens new avenues for exploration in the field of 3D representation and pose estimation. The success of this method in surpassing traditional and learning-based pose prediction techniques underscores the potential of adopting more complex, distributed representations for neural learning, paving the way for future advancements in this domain.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post CMU Researchers Unveil Groundbreaking AI Method for Camera Pose Estimation: Harnessing Ray Diffusion for Enhanced 3D Reconstruction appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]