


There is a steadily growing list of intriguing properties of neural network (NN) optimization that are not readily explained by classical tools from optimization. Likewise, the research team has varying degrees of understanding of the mechanical causes for each. Extensive efforts have led to possible explanations for the effectiveness of Adam, Batch Normalization, and other tools for successful training, but the evidence is only sometimes entirely convincing, and there is certainly little theoretical understanding. Other findings, such as grokking or the edge of stability, do not have immediate practical implications but provide new ways to study what sets NN optimization apart. These phenomena are typically considered in isolation, though they are not completely disparate; it is unknown what specific underlying causes they may share. A better understanding of NN training dynamics in a particular context can lead to algorithmic improvements; this suggests that any commonality will be a valuable tool for further investigation.
In this work, the research team from Carnegie Mellon University identifies a phenomenon in neural network NN optimization that offers a new perspective on many of these prior observations, which the research team hopes will contribute to a deeper understanding of how they may be connected. While the research team does not claim to give a complete explanation, it presents strong qualitative and quantitative evidence for a single high-level idea, which naturally fits into several existing narratives and suggests a more coherent picture of their origin. Specifically, the research team demonstrates the prevalence of paired groups of outliers in natural data, which significantly influence a network’s optimization dynamics. These groups include one or more (relatively) large-magnitude features that dominate the network’s output at initialization and throughout most of the training. In addition to their magnitude, the other distinctive property of these features is that they provide large, consistent, and opposing gradients, in that following one group’s gradient to decrease its loss will increase the other’s by a similar amount. Because of this structure, the research team refers to them as Opposing Signals. These features share a non-trivial correlation with the target task but are often not the “correct” (e.g., human-aligned) signal.
In many cases, these features perfectly encapsulate the classic statistical conundrum of “correlation vs. causation.” For example, a bright blue sky background does not determine the label of a CIFAR image, but it does most often occur in images of planes. Other features are relevant, such as the presence of wheels and headlights in images of trucks and cars or that a colon often precedes either “the” or a newline token in written text. Figure 1 depicts the training loss of a ResNet-18 trained with full-batch gradient descent (GD) on CIFAR-10, along with a few dominant outlier groups and their respective losses.
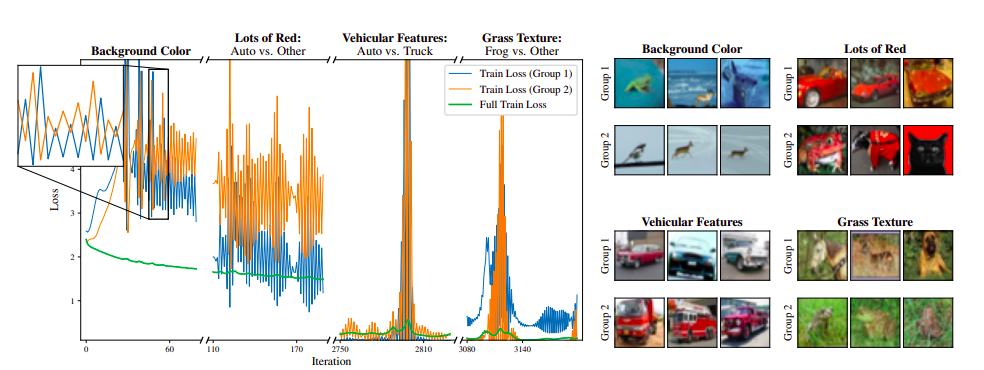
In the early stages of training, the network enters a narrow valley in weight space, which carefully balances the pairs’ opposing gradients; subsequent sharpening of the loss landscape causes the network to oscillate with growing magnitude along particular axes, upsetting this balance. Returning to their example of a sky background, one step results in the class plane being assigned greater probability for all images with sky, and the next will reverse that effect. In essence, the “sky = plane” subnetwork grows and shrinks.1 The direct result of this oscillation is that the network’s loss on images of planes with a sky background will alternate between sharply increasing and decreasing with growing amplitude, with the exact opposite occurring for images of non-planes with the sky. Consequently, the gradients of these groups will alternate directions while growing in magnitude as well. As these pairs represent a small fraction of the data, this behavior is not immediately apparent from the overall training loss. Still, eventually, it progresses far enough that the broad loss spikes.
As there is an obvious direct correspondence between these two events throughout, the research team conjectures that opposing signals directly cause the edge of stability phenomenon. The research team also notes that the most influential signals appear to increase in complexity over time. The research team repeated this experiment across a range of vision architectures and training hyperparameters: though the precise groups and their order of appearance change, the pattern occurs consistently. The research team also verified this behavior for transformers on next-token prediction of natural text and small ReLU MLPs on simple 1D functions. However, the research team relies on images for exposition because they offer the clearest intuition. Most of their experiments use GD to isolate this effect, but the research team observed similar patterns during SGD—summary of contributions. The primary contribution of this paper is demonstrating the existence, pervasiveness, and large influence of opposing signals during NN optimization.
The research team further presents their current best understanding, with supporting experiments, of how these signals cause the observed training dynamics. In particular, the research team provides evidence that it is a consequence of depth and steepest descent methods. The research team complements this discussion with a toy example and an analysis of a two-layer linear net on a simple model. Notably, though rudimentary, their explanation enables concrete qualitative predictions of NN behavior during training, which the research team confirms experimentally. It also provides a new lens through which to study modern stochastic optimization methods, which the research team highlights via a case study of SGD vs. Adam. The research team sees possible connections between opposing signals and various NN optimization and generalization phenomena, including grokking, catapulting/slingshotting, simplicity bias, double descent, and Sharpness-Aware Minimization.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post CMU Researchers Discover Key Insights into Neural Network Behavior: The Interplay of Heavy-Tailed Data and Network Depth in Shaping Optimization Dynamics appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]