


Multimodal large language models (MLLMs) are advancing the integration of NLP and computer vision, essential for analyzing visual and textual data. These models are particularly valuable for interpreting complex charts in scientific papers, financial reports, and other documents. The primary challenge is enhancing these models’ ability to comprehend and interpret such charts. However, current benchmarks often need to be more accurate to justify this task, leading to overestimating MLLM capabilities. The issue stems from the lack of diverse and realistic datasets that reflect real-world scenarios, which is crucial for evaluating the true performance of these models.
A significant problem in MLLM research is the oversimplification found in existing benchmarks. Datasets like FigureQA, DVQA, and ChartQA rely on procedurally generated questions and charts that need more visual diversity and complexity. These benchmarks need to capture the true intricacies of real-world charts, as they use template-based questions and homogeneous chart designs. This limitation results in an inaccurate assessment of a model’s chart understanding capabilities, as the benchmarks must adequately challenge the models. Consequently, there is a pressing need for more realistic and diverse datasets to provide a robust measure of MLLM performance in interpreting complex charts.
Researchers from Princeton University, the University of Wisconsin, and The University of Hong Kong have introduced CharXiv, a comprehensive evaluation suite designed to provide a more realistic and challenging assessment of MLLM performance. CharXiv includes 2,323 charts from arXiv papers, encompassing various subjects and chart types. These charts are paired with descriptive and reasoning questions that require detailed visual and numerical analysis. The dataset covers eight major academic subjects and features diverse and complex charts to thoroughly test the models’ capabilities. CharXiv aims to bridge the gap between current benchmarks and real-world applications by offering a more accurate and demanding evaluation environment for MLLMs.
CharXiv distinguishes itself through its meticulously curated questions and charts, designed to assess both the descriptive and reasoning capabilities of MLLMs. Descriptive questions focus on basic chart elements, such as titles, labels, and ticks, while reasoning questions require synthesizing complex visual information and numerical data. Human experts handpicked, curated, and verified all charts and questions to ensure high quality and relevance. This meticulous curation process aims to provide a realistic benchmark that challenges MLLMs more effectively than existing datasets, ultimately leading to improved model performance and reliability in practical applications.
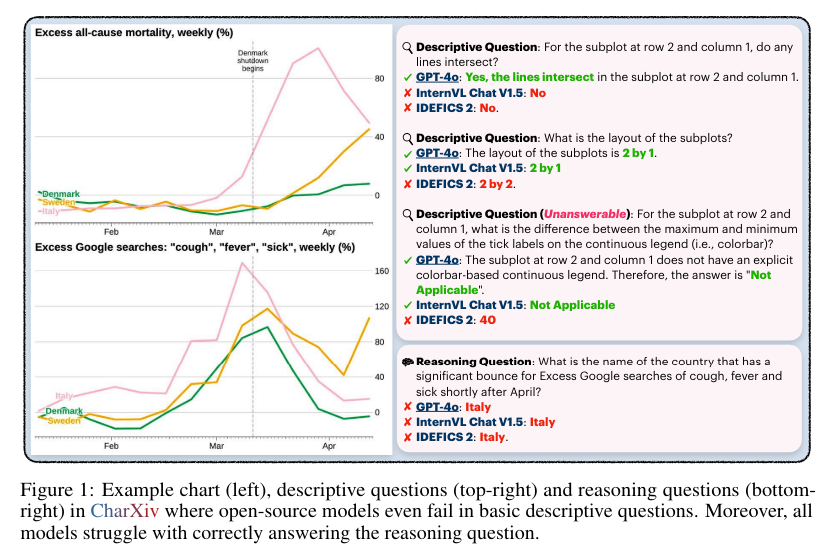
In evaluating CharXiv, researchers conducted extensive tests on 13 open-source and 11 proprietary models, revealing a substantial performance gap. The strongest proprietary model, GPT-4o, achieved 47.1% accuracy on reasoning questions and 84.5% on descriptive questions. In contrast, the leading open-source model, InternVL Chat V1.5, managed only 29.2% accuracy on reasoning questions and 58.5% on descriptive ones. These results underscore the challenges that current MLLMs face in chart understanding, as human performance on these tasks was notably higher, with 80.5% accuracy on reasoning questions and 92.1% on descriptive questions. This performance disparity highlights the need for more robust and challenging benchmarks like CharXiv to drive further advancements in the field.

The findings from CharXiv provide critical insights into the strengths and weaknesses of current MLLMs. For instance, the performance gap between proprietary and open-source models suggests that the former are better equipped to handle the complexity & diversity of real-world charts. The evaluation revealed that descriptive skills are a prerequisite for effective reasoning, as models with strong descriptive capabilities tend to perform better on reasoning tasks. Models also need help with compositional tasks, such as counting labeled ticks on axes, which are simple for humans but challenging for MLLMs.
In conclusion, CharXiv addresses the critical shortcomings of existing benchmarks. By providing a more realistic and challenging dataset, CharXiv enables a more accurate assessment of MLLM performance in interpreting complex charts. The substantial performance gaps identified in the study highlight the need for continued research and improvement. CharXiv’s comprehensive approach aims to drive future advancements in MLLM capabilities, ultimately leading to more reliable and effective models for practical applications.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
 Create, edit, and augment tabular data with the first compound AI system, Gretel Navigator, now generally available! [Advertisement]
Create, edit, and augment tabular data with the first compound AI system, Gretel Navigator, now generally available! [Advertisement]
The post CharXiv: A Comprehensive Evaluation Suite Advancing Multimodal Large Language Models Through Realistic Chart Understanding Benchmarks appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]