


In machine learning, larger networks with increasing parameters are being trained. However, training such networks has become prohibitively expensive. Despite the success of this approach, there needs to be a greater understanding of why overparameterized models are necessary. The costs associated with training these models continue to rise exponentially.
A team of researchers from the University of Massachusetts Lowell, Eleuther AI, and Amazon developed a method known as ReLoRA, which uses low-rank updates to train high-rank networks. ReLoRA accomplishes a high-rank update, delivering a performance akin to conventional neural network training.
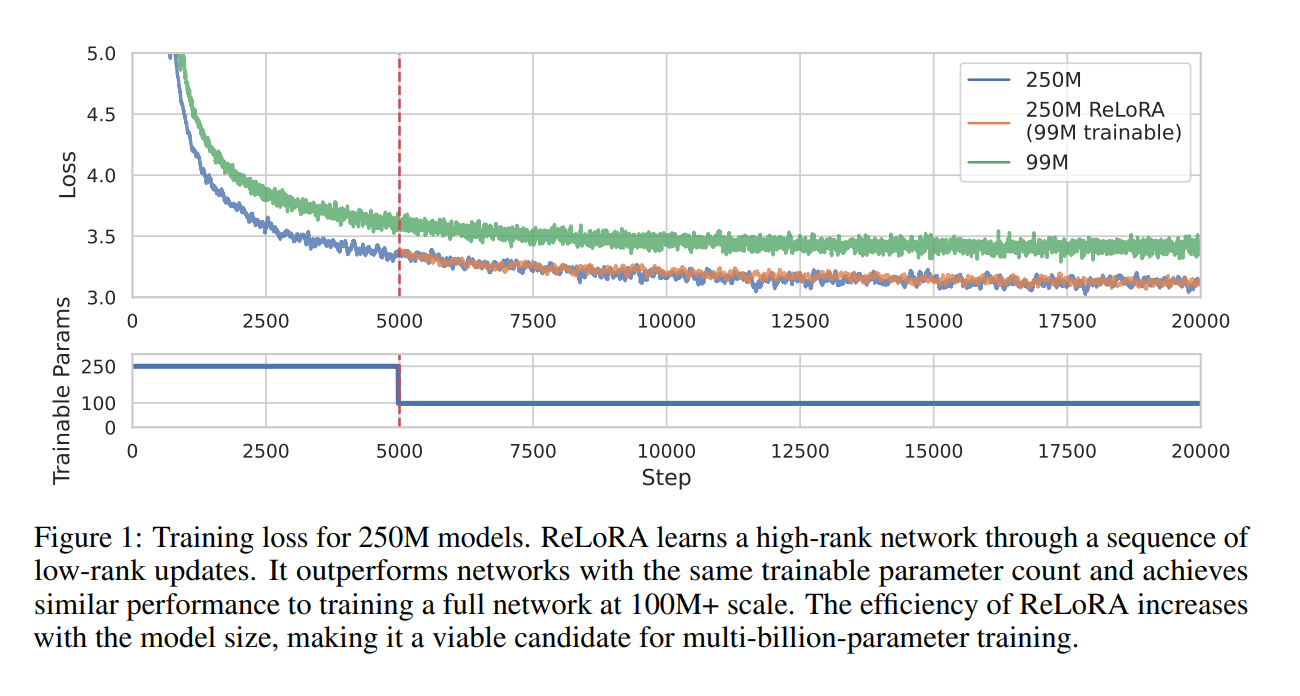
Scaling laws have been identified, demonstrating a strong power-law dependence between network size and performance across different modalities, supporting overparameterization and resource-intensive neural networks. The Lottery Ticket Hypothesis suggests that overparameterization can be minimized, providing an alternative perspective. Low-rank fine-tuning methods, such as LoRA and Compacter, have been developed to address the limitations of low-rank matrix factorization approaches.
ReLoRA is applied to training transformer language models with up to 1.3B parameters and demonstrates comparable performance to regular neural network training. The ReLoRA method leverages the rank of the sum property to train a high-rank network through multiple low-rank updates. ReLoRA employs a full-rank training warm start before transitioning to ReLoRA and periodically merges its parameters into the main parameters of the network, performs optimizer reset, and learning rate re-warm up. The Adam optimizer and a jagged cosine scheduler are also used in ReLoRA.
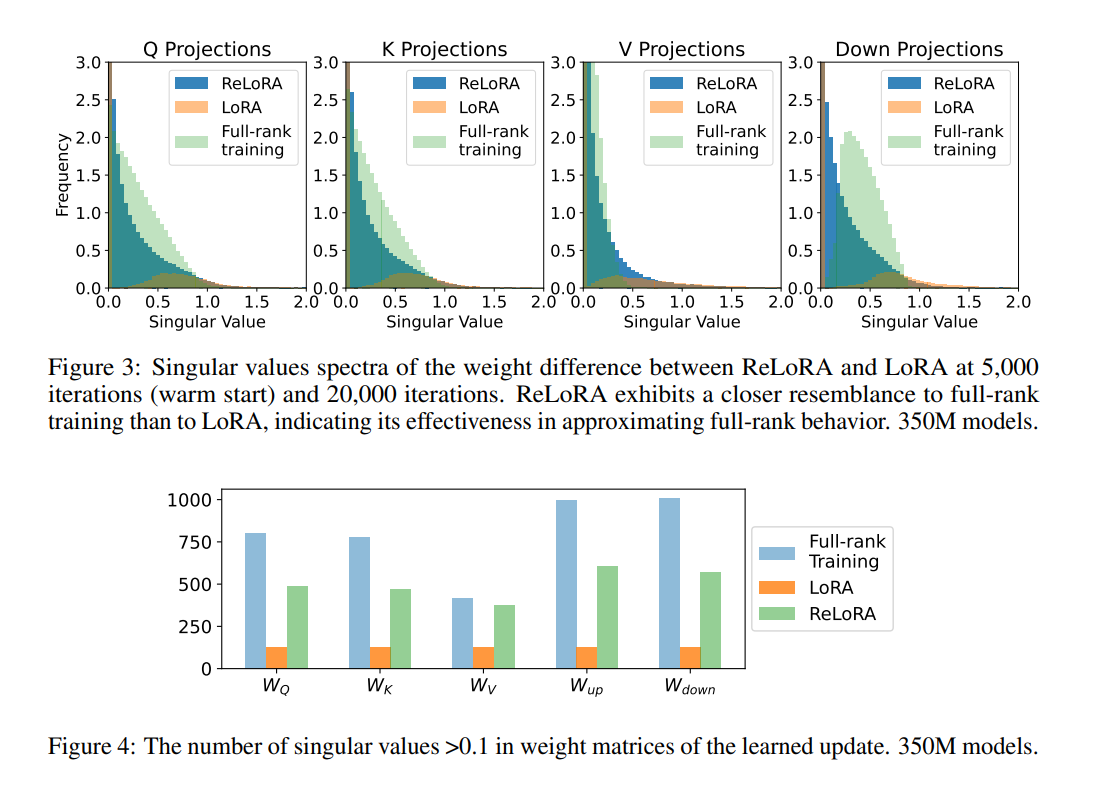
ReLoRA performs comparable to regular neural network training in upstream and downstream tasks. The method saves up to 5.5Gb of RAM per GPU and improves training speed by 9-40%, depending on the model size and hardware setup. Qualitative analysis of the singular value spectrum shows that ReLoRA exhibits a higher distribution mass between 0.1 and 1.0, reminiscent of full-rank training, while LoRA has mostly zero distinct values.
In conclusion, the study can be summarized in below points:
- ReLoRA accomplishes a high-rank update by performing multiple low-rank updates.
- It has a smaller number of near-zero singular values compared to LoRA.
- ReLoRA is a parameter-efficient training technique that utilizes low-rank updates to train large neural networks with up to 1.3B parameters.
- It saves significant GPU memory up to 5.5Gb per GPU and improves training speed by 9-40%, depending on the model size and hardware setup.
- ReLoRA outperforms the low-rank matrix factorization approach in training high-performing transformer models.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post Can We Train Massive Neural Networks More Efficiently? Meet ReLoRA: the Game-Changer in AI Training appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]