


Scientific discovery has been a cornerstone of human advancement for centuries, traditionally relying on manual processes. However, the emergence of large language models (LLMs) with advanced reasoning capabilities and the ability to interact with external tools and agents has opened up new possibilities for autonomous discovery systems. The challenge lies in developing a fully autonomous system capable of generating and verifying hypotheses within the realm of data-driven discovery. While recent studies have shown promising results in this direction, the full extent of LLMs’ potential in scientific discovery remains uncertain. Researchers are now faced with the task of exploring and expanding the capabilities of these AI systems to revolutionize the scientific process, potentially accelerating the pace of discovery and innovation across various fields.
Previous attempts at automated data-driven discovery have ranged from early systems like Bacon, which fitted equations to idealized data, to more advanced solutions like AlphaFold, capable of handling complex real-world problems. However, these systems often relied on task-specific datasets and pre-built pipelines. AutoML tools, such as Scikit and cloud-based solutions, have made strides in automating machine learning workflows, but their datasets are primarily used for model training rather than open-ended discovery tasks. Similarly, statistical analysis datasets and software packages like Tableaux, SAS, and R support data analysis but are limited in scope. The QRData dataset represents a step towards exploring LLM capabilities in statistical and causal analysis, but it focuses on well-defined questions with unique, primarily numeric answers. These existing approaches, while valuable, need to provide a comprehensive solution for automating the entire discovery process, including ideation, semantic reasoning, and pipeline design.
Researchers from the Allen Institute for AI, OpenLocus, and the University of Massachusetts Amherst propose DISCOVERYBENCH which aims to systematically evaluate the capabilities of state-of-the-art large language models (LLMs) in automated data-driven discovery. This benchmark addresses the challenges of diversity in real-world data-driven discovery across various domains by introducing a pragmatic formalization. It defines discovery tasks as searching for relationships between variables within a specific context, where the description of these elements may not directly correspond to the dataset’s language. This approach allows for systematic and reproducible evaluation of a wide range of real-world problems by utilizing key facets of the discovery process.
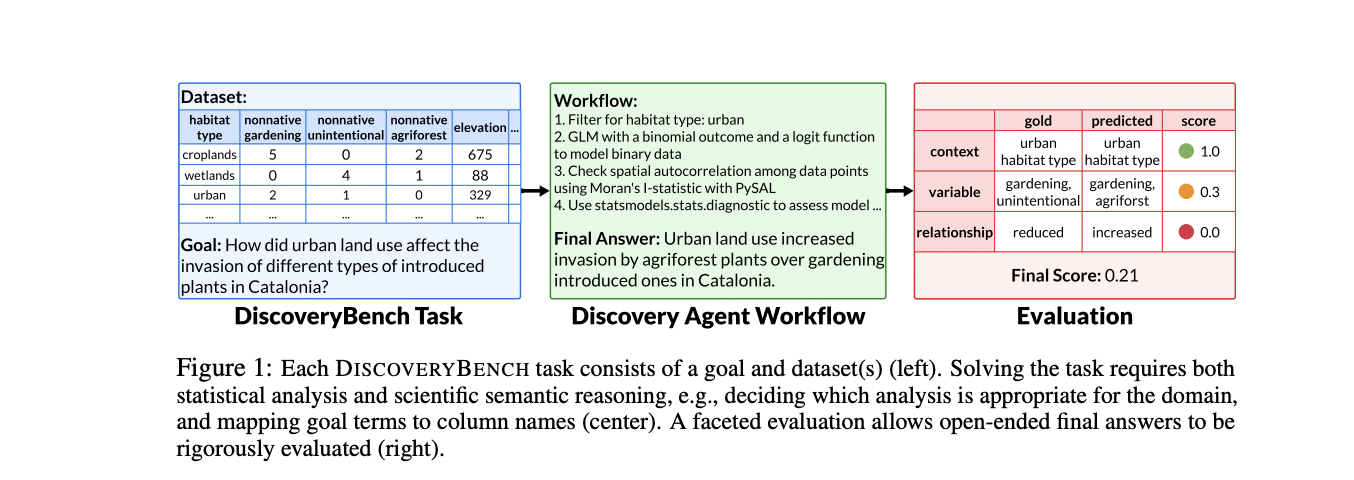
DISCOVERYBENCH distinguishes itself from previous datasets for statistical analysis or AutoML by incorporating scientific semantic reasoning. This includes deciding on appropriate analysis techniques for specific domains, data cleaning and normalization, and mapping goal terms to dataset variables. The tasks typically require multistep workflows, addressing the broader data-driven discovery pipeline rather than focusing solely on statistical analysis. This comprehensive approach makes DISCOVERYBENCH the first large-scale dataset to explore LLMs’ capacity for the entire discovery process.
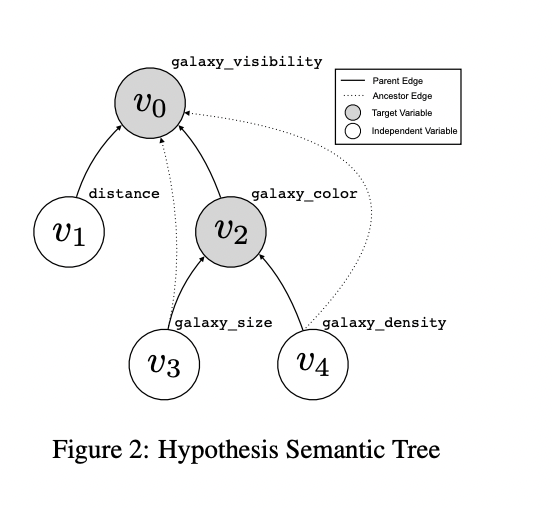
In this method, researchers begin by formalizing data-driven discovery by introducing a structured approach to hypothesis representation and evaluation. It defines hypotheses as declarative sentences verifiable through datasets, breaking them down into contexts, variables, and relationships. The key innovation is the Hypothesis Semantic Tree, a hierarchical structure representing complex hypotheses with interconnected variables. This tree allows for encoding multiple hypotheses within a single structure. The method also formalizes task datasets as collections of tuples supporting multiple hypothesis semantic trees, with varying degrees of observability. This framework provides a flexible yet rigorous approach to representing and evaluating complex discovery problems, enabling systematic assessment of automated discovery systems.
DISCOVERYBENCH consists of two main components: DB-REAL and DB-SYNTH. DB-REAL encompasses real-world hypotheses and workflows derived from published scientific papers across six domains: sociology, biology, humanities, economics, engineering, and meta-science. It includes tasks that often require analysis of multiple datasets, with workflows ranging from basic data preparation to advanced statistical analyses. DB-SYNTH, on the other hand, is a synthetically generated benchmark that allows for controlled model evaluations. It uses large language models to generate diverse domains, construct semantic hypothesis trees, create synthetic datasets, and formulate discovery tasks of varying difficulty. This dual approach allows DISCOVERYBENCH to capture both the complexity of real-world discovery problems and the systematic variation needed for comprehensive model evaluation.

The study evaluates several discovery agents powered by different language models (GPT-4o, GPT-4p, and Llama-3-70B) on the DISCOVERYBENCH dataset. The agents include CodeGen, ReAct, DataVoyager, Reflexion (Oracle), and NoDataGuess. Results show that overall performance is low across all agent-LLM pairs for both DB-REAL and DB-SYNTH, highlighting the benchmark’s challenging nature. Surprisingly, advanced reasoning prompts (React) and planning with self-criticism (DataVoyager) do not significantly outperform the simple CodeGen agent. However, Reflexion (Oracle), which uses feedback for improvement, shows notable gains over CodeGen. The study also reveals that non-reflexion agents mainly solve the easiest instances, and performance on DB-REAL and DB-SYNTH is similar, validating the synthetic benchmark’s ability to capture real-world complexities.
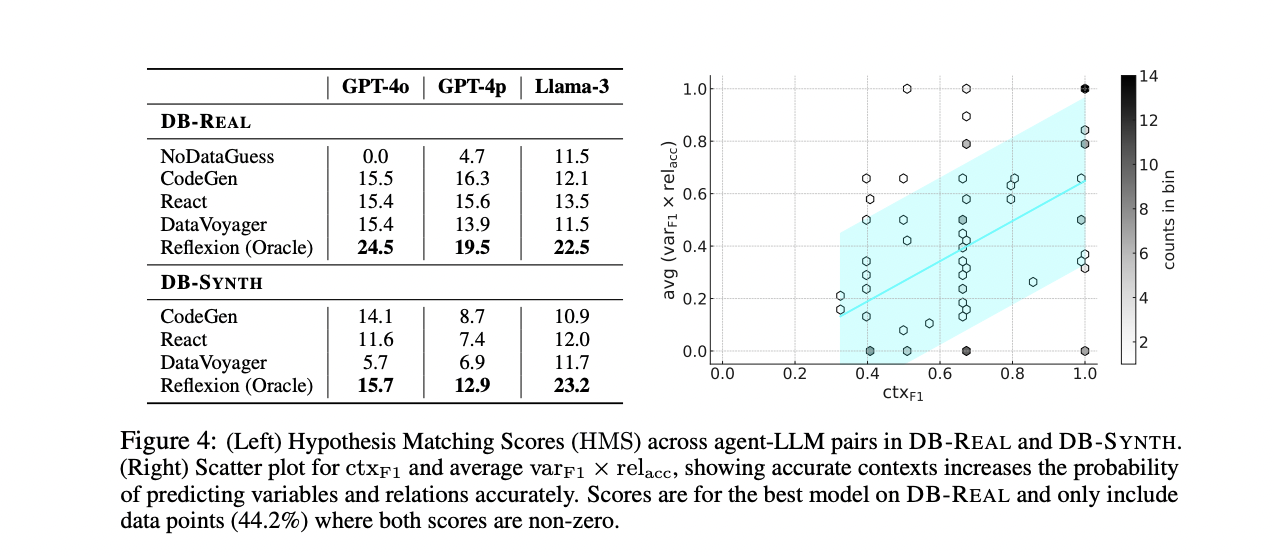
DISCOVERYBENCH represents a significant advancement in evaluating automated data-driven discovery systems. This comprehensive benchmark includes 264 real-world discovery tasks derived from published scientific workflows, complemented by 903 synthetically generated tasks designed to assess discovery agents at various difficulty levels. Despite employing state-of-the-art reasoning frameworks powered by advanced large language models, the best-performing agent only achieves a 25% success rate. This modest performance underscores the challenging nature of automated scientific discovery and highlights the considerable room for improvement in this field. By providing this timely and robust evaluation framework, DISCOVERYBENCH aims to stimulate increased interest and research efforts in developing more reliable and reproducible autonomous scientific discovery systems using large generative models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Can LLMs Help Accelerate the Discovery of Data-Driven Scientific Hypotheses? Meet DiscoveryBench: A Comprehensive LLM Benchmark that Formalizes the Multi-Step Process of Data-Driven Discovery appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #TechNews #Technology #Uncategorized [Source: AI Techpark]