


The development of Multi-modal Large Language Models (MLLMs) represents a groundbreaking shift in the fast-paced field of artificial intelligence. These advanced models, which integrate the robust capabilities of Large Language Models (LLMs) with enhanced sensory inputs such as visual data, are redefining the boundaries of machine learning and AI. The surge of interest in MLLMs, exemplified by OpenAI’s GPT-4V, underscores a significant trend in academic and industry settings. These models are not just about processing vast amounts of text but about creating a more holistic understanding by combining textual data with visual insights. A new research paper from Tencent Youtu Lab, Shanghai AI Laboratory, CUHK MMLab, USTC, Peking University, and ECNU presents an in-depth exploration of Google’s latest MLLM, Gemini, which emerges as a potential challenger to the current leader in the field, GPT-4V. The study meticulously examines Gemini’s capabilities in visual expertise and multi-modal reasoning, setting the stage for a comprehensive assessment of its position in the rapidly evolving landscape of MLLMs.
GPT-4V from OpenAI currently stands as a benchmark in MLLMs, showcasing remarkable multi-modal abilities across various benchmarks. However, the release of Gemini by Google presents a new dynamic. This paper contrasts Gemini’s capabilities with GPT-4V alongside the Sphinx model, a state-of-the-art, open-sourced MLLM. The comparison aims to elucidate the differences in performance between open-sourced and closed-sourced systems in the MLLM domain.
Gemini, Google’s latest MLLM, is explored for its proficiency in visual understanding. The researchers examined Gemini Pro, covering several domains like basic perception, advanced cognition, and expert-level tasks. This approach tests Gemini’s limits and provides a broad spectrum analysis of its multi-modal understanding capabilities.
The methodology adopted for evaluating Gemini involves a deep dive into various dimensions of visual understanding. These include object-centric perception, scene-level understanding, knowledge application, advanced cognition, and handling of challenging visual tasks. The performance of Gemini is meticulously compared with GPT-4V and Sphinx across these domains, offering a nuanced understanding of its strengths and weaknesses.
Gemini demonstrates a robust challenge to GPT-4V, matching or surpassing it in several aspects of visual reasoning. In contrast to GPT-4V’s preference for detailed explanations, Gemini opts for direct and concise responses, highlighting differences in answering styles. While competitive, Sphinx does not match its peers’ overall domain generalizability. The quantitative analysis further underscores Gemini’s impressive multi-modal understanding, suggesting its potential to rival GPT-4V in the MLLM landscape.
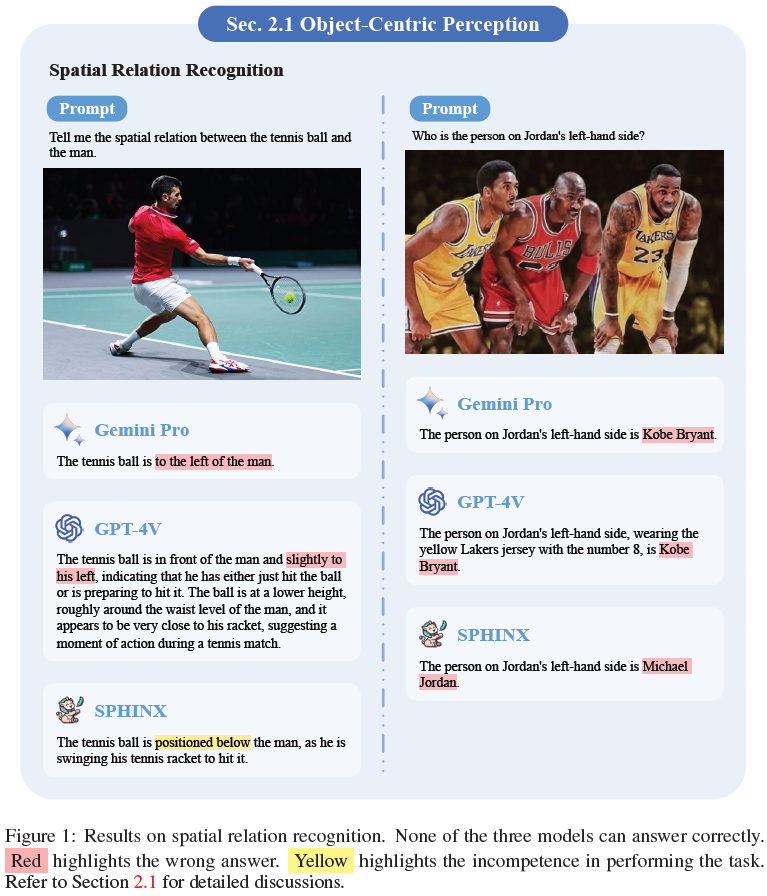
The exploration of Gemini Pro reveals its significant potential as a competitor to GPT-4V in multi-modal learning. This work sheds light on the current capabilities of these advanced models and uncovers common challenges, such as spatial perception and logical reasoning inconsistencies. These findings are crucial for guiding future MLLM research and applications.
In conclusion, this research provides valuable insights into the evolving world of MLLMs. Gemini, with its unique strengths, alongside GPT-4V and Sphinx, collectively push the boundaries of multi-modal understanding. This study highlights the ongoing advancements in the field and the strides toward achieving more comprehensive forms of artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post Can Google’s Gemini Rival OpenAI’s GPT-4V in Visual Understanding?: This Paper Explores the Battle of Titans in Multi-modal AI appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]