


In the rapidly evolving field of artificial intelligence, the development and application of large language models (LLMs) stand at the forefront of innovation, offering unparalleled data processing and analysis capabilities. These sophisticated models, characterized by their vast parameter spaces, have demonstrated exceptional proficiency in various tasks, from natural language processing to complex problem-solving. However, the deployment of LLMs has challenges, particularly when balancing computational efficiency and maintaining high-performance levels. The crux of the matter lies in the inherent trade-off: leveraging the full power of LLMs often requires substantial computational resources, which can be both costly and time-consuming.
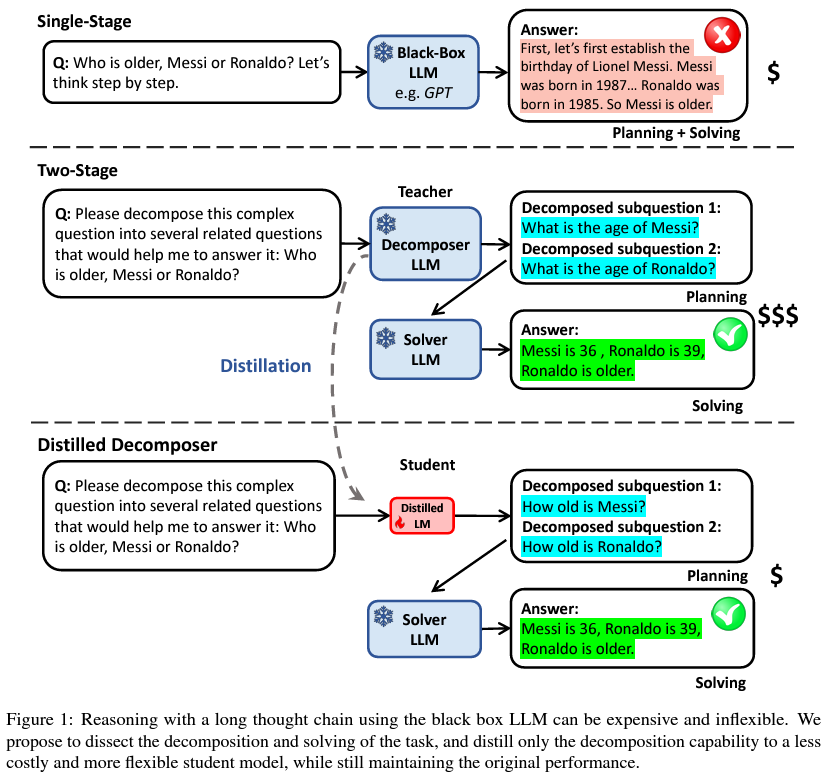
Recognizing this, researchers from the University of Michigan and tech giant Apple embarked on an ambitious project to refine the utilization of LLMs, specifically targeting the model’s efficiency without sacrificing its effectiveness. Their innovative approach centers on distillation, a process designed to streamline the model’s operations by focusing on two critical phases of task execution: problem decomposition and problem-solving. The essence of their strategy lies in the hypothesis that problem decomposition—the initial phase where complex tasks are broken down into simpler subtasks—can be distilled into smaller, more manageable models with greater ease compared to the problem-solving phase.
To test this hypothesis, the research team conducted a series of experiments to distill the decomposition capability of LLMs into smaller models. This involved separating the decomposition task from the overall problem-solving process, allowing for a targeted optimization of this initial phase. The results of their efforts were compelling: not only did the distilled decomposition models retain a high level of performance across various tasks and datasets, but they also achieved this with significantly reduced computational demands. In practical terms, this translates to a more cost-effective and efficient use of LLMs, enabling faster inference times without compromising on the quality of outcomes.
A closer examination of the performance metrics further underscores the effectiveness of the distilled models. The research team observed that the decomposed models demonstrated remarkable generalization capabilities in their experiments, performing consistently well across different tasks and datasets. Specifically, the distilled models achieved a performance level that closely mirrored that of their larger LLM counterparts but with a notable reduction in inference costs. For instance, in tasks related to mathematical reasoning and question answering, the distilled models maintained performance levels while significantly cutting down on the computational resources required.
This breakthrough research, spearheaded by the collaboration between the University of Michigan and Apple, marks a significant advancement in artificial intelligence. By successfully distilling the decomposition phase of LLMs into smaller models, the team has opened up new avenues for the efficient and effective use of these powerful tools. Their findings not only highlight the potential for cost savings and increased accessibility to LLM technology but also set the stage for further exploration into optimizing LLMs for various applications.
This work presents a compelling case for the targeted distillation of LLM capabilities as a viable strategy for enhancing model efficiency. The implications of such an approach are far-reaching, promising to accelerate the adoption and application of LLMs across a broad spectrum of industries and research domains. As the field continues to evolve, the insights gained from this project will undoubtedly contribute to the ongoing dialogue on how best to leverage the immense potential of large language models in a way that is both sustainable and impactful.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Can AI Think Better by Breaking Down Problems? Insights from a Joint Apple and University of Michigan Study on Enhancing Large Language Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]