


Text-to-image (T2I) and text-to-video (T2V) generation have made significant strides in generative models. While T2I models can control subject identity well, extending this capability to T2V remains challenging. Existing T2V methods need more precise control over generated content, particularly identity-specific generation for human-related scenarios. Efforts to leverage T2I advancements for video generation need help maintaining consistent identities and stable backgrounds across frames. These challenges stem from diverse reference images influencing identity tokens and the struggle of motion modules to ensure temporal consistency amidst varying identity inputs.
Researchers from ByteDance Inc. and UC Berkeley have developed Video Custom Diffusion (VCD), a straightforward yet potent framework for generating subject identity-controllable videos. VCD employs three key components: an ID module for precise identity extraction, a 3D Gaussian Noise Prior for inter-frame consistency, and V2V modules to enhance video quality. By disentangling identity information from background noise, VCD aligns IDs accurately, ensuring stable video outputs. The framework’s flexibility allows it to work seamlessly with various AI-generated content models. Contributions include significant advancements in ID-specific video generation, robust denoising techniques, resolution enhancement, and a training approach for noise mitigation in ID tokens.

In generative models, T2I generation advancements have led to customizable models capable of creating realistic portraits and imaginative compositions. Techniques like Textual Inversion and DreamBooth fine-tune pre-trained models with subject-specific images, generating unique identifiers linked to desired subjects. This progress extends to multi-subject generation, where models learn to compose multiple subjects into single images. Transitioning to T2V generation presents new challenges due to the need for spatial and temporal consistency across frames. While early methods utilized GANs and VAEs for low-resolution videos, recent approaches employed diffusion models for higher-quality output.
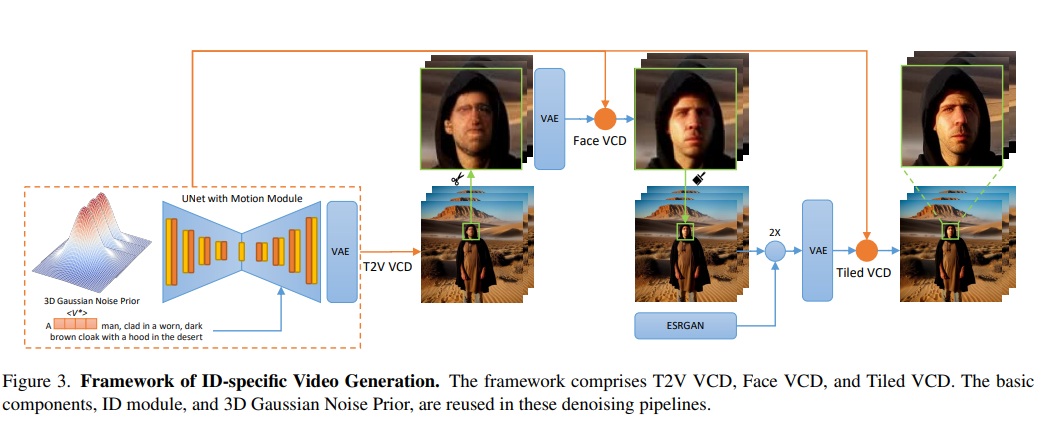
A preprocessing module, ID module, and motion module have been used in the VCD framework. Additionally, an optional ControlNet Tile module upsamples videos for higher resolution. VCD enhances an off-the-shelf motion module with a 3D Gaussian Noise before mitigating exposure bias during inference. The ID module incorporates extended ID tokens with masked loss and prompt-to-segmentation, effectively removing background noise. The study also mentions two V2V VCD pipelines: Face VCD, which enhances facial features and resolution, and Tiled VCD, which further upscales the video while preserving identity details. These modules collectively ensure high-quality, identity-preserving video generation.
VCD model maintains character identity across various realistic and stylized models. The researchers meticulously selected subjects from diverse datasets and evaluated the method against multiple baselines using CLIP-I and DINO for identity alignment, text alignment, and temporal smoothness. The training details involved using Stable Diffusion 1.5 for the ID module and adjusting learning rates and batch sizes accordingly. The study sourced data from DreamBooth and CustomConcept101 datasets and evaluated the model’s performance against various metrics. The study highlighted the critical role of the 3D Gaussian Noise Prior and prompt-to-segmentation module in enhancing video smoothness and image alignment. Realistic Vision generally outperformed Stable Diffusion, underscoring the importance of model selection.

In conclusion, VCD revolutionizes subject identity controllable video generation by seamlessly integrating identity information and frame-wise correlation. Through innovative components like the ID module, trained with prompt-to-segmentation for precise identity disentanglement, and the T2V VCD module for enhanced frame consistency, VCD sets a new benchmark for video identity preservation. Its adaptability with existing text-to-image models enhances practicality. With features like the 3D Gaussian Noise Prior and Face/Tiled VCD modules, VCD ensures stability, clarity, and higher resolution. Extensive experiments confirm its superiority over existing methods, making it an indispensable tool for generating stable, high-quality videos with preserved identity.
Check out the Paper, Github, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post ByteDance Proposes Magic-Me: A New AI Framework for Video Generation with Customized Identity appeared first on MarkTechPost.
#AIShorts #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]