


Evaluating the effectiveness of Large Language Model (LLM) compression techniques is a crucial challenge in AI. Compression methods like quantization aim to optimize LLM efficiency by reducing computational costs and latency. However, traditional evaluation practices focus primarily on accuracy metrics, which fail to capture changes in model behavior, such as the phenomenon of “flips” where correct answers turn incorrect and vice versa. This challenge is significant as it impacts the reliability and consistency of compressed models in various critical applications, including medical diagnosis and autonomous driving.
Current methods for evaluating LLM compression techniques rely heavily on accuracy metrics from benchmark tasks like MMLU, Hellaswag, and ARC. These methods involve measuring the performance of compressed models against baseline models by comparing their accuracy on predefined tasks. However, this approach overlooks the occurrence of flips, where compressed models may produce different answers despite having similar accuracy levels. This can lead to a misleading perception of the model’s reliability. Moreover, accuracy metrics alone do not account for qualitative differences in model behavior, especially in tasks involving generative responses, where the nuances of language generation are critical.
The researchers from Microsoft Research, India, propose a novel approach to evaluating LLM compression techniques by introducing distance metrics such as KL-Divergence and % flips, in addition to traditional accuracy metrics. This approach provides a more comprehensive evaluation of how closely compressed models mimic their baseline counterparts. The core innovation lies in the identification and quantification of flips, which serve as an intuitive and easily interpretable metric of model divergence. By focusing on both qualitative and quantitative aspects of model performance, this approach ensures that compressed models maintain high standards of reliability and applicability across various tasks.
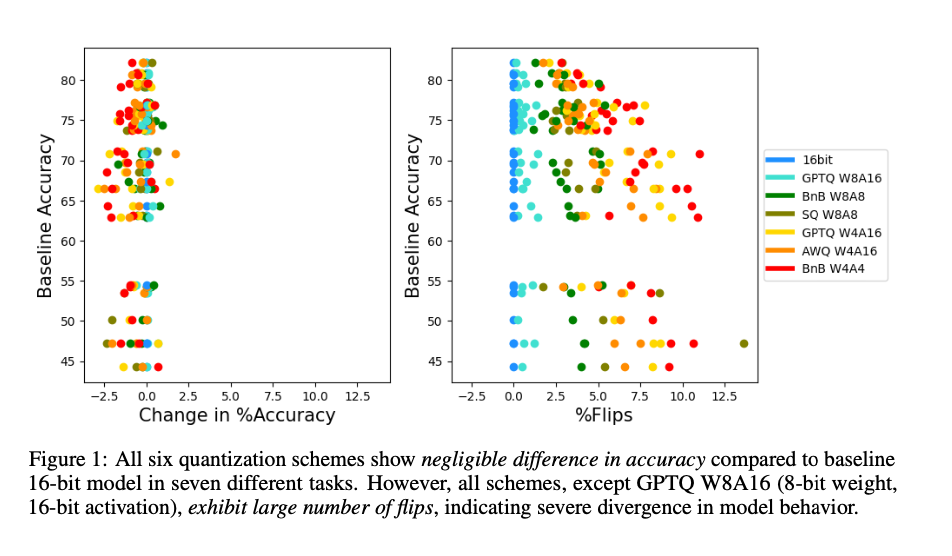
The study details experiments conducted using multiple LLMs (e.g., Llama2 and Yi chat models) and various quantization techniques (e.g., LLM.int8, GPTQ, AWQ). The researchers evaluate these techniques on several tasks, including MMLU, ARC, PIQA, Winogrande, Hellaswag, and Lambada. The evaluation metrics include accuracy, perplexity, flips, and KL-Divergence. Notably, the flips metric measures the percentage of answers that change from correct to incorrect and vice versa between the baseline and compressed models. The dataset characteristics and hyperparameter tuning strategies for each model are carefully outlined, ensuring a robust experimental setup.
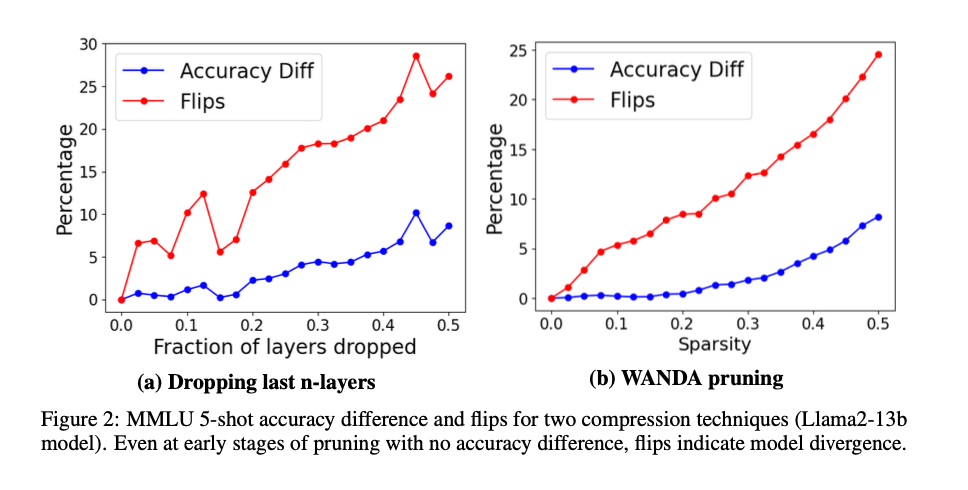
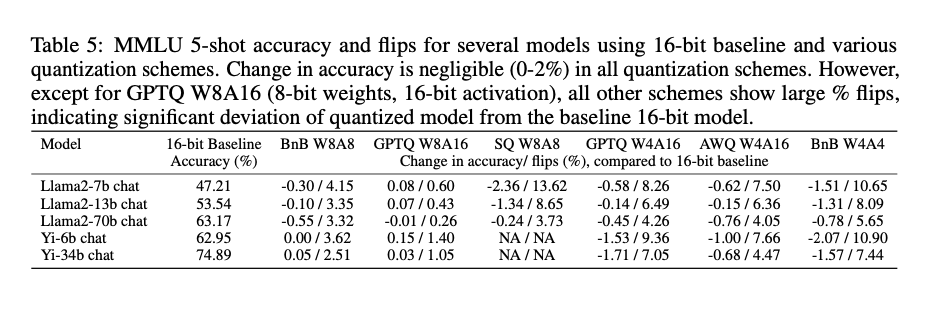
The findings reveal that while accuracy differences between baseline and compressed models are often negligible (≤2%), the percentage of flips can be substantial (≥5%), indicating significant divergence in model behavior. For instance, in the MMLU task, the GPTQ W8A16 quantization scheme achieves an accuracy of 63.17% with only a 0.26% flip rate, demonstrating high fidelity to the baseline model. In contrast, other quantization schemes show significant deviations, with flip rates as high as 13.6%. The study also shows that larger models typically have fewer flips than smaller ones, indicating greater resilience to compression. Additionally, qualitative evaluation using MT-Bench reveals that models with higher flip rates perform worse in generative tasks, further validating the proposed metrics’ effectiveness in capturing nuanced performance changes.
In conclusion, this proposed method makes a significant contribution to AI research by proposing a more comprehensive evaluation framework for LLM compression techniques. It identifies the limitations of relying solely on accuracy metrics and introduces the flips and KL-Divergence metrics to better capture model divergence. This approach ensures that compressed models maintain high reliability and applicability, advancing the field of AI by addressing a critical challenge in model evaluation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Beyond Accuracy: Evaluating LLM Compression with Distance Metrics appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]