


Large language models (LLMs) have achieved remarkable success across various domains, but training them centrally requires massive data collection and annotation efforts, making it costly for individual parties. Federated learning (FL) has emerged as a promising solution, enabling collaborative training of LLMs on decentralized data while preserving privacy (FedLLM). Although frameworks like OpenFedLLM, FederatedScope-LLM, and FedML-LLM have been developed along with methods tackling data quality, intellectual property, privacy, and resource constraints in FedLLM, a significant challenge remains the lack of realistic benchmarks. Current works construct artificial FL datasets by partitioning centralized datasets, failing to capture properties of real-world cross-user data.
Numerous methods have been proposed to address data heterogeneity in federated learning, a major challenge where clients’ datasets come from different distributions. These include regularization, gradient correction, feature alignment, adjusting aggregation weights, introducing momentum, and leveraging pre-trained models. While FedLLM has gained traction recently, with frameworks like OpenFedLLM, FederatedScope-LLM, FedML-LLM, and methods like FedbiOT for model property protection and FFA-LoRA for differential privacy, a significant limitation persists. Previous works evaluate artificially crafted federated datasets by partitioning centralized datasets, failing to capture the complexities of real-world cross-user data.
Researchers from Shanghai Jiao Tong University, Tsinghua University, and Shanghai AI Laboratory propose FedLLM-Bench, the first realistic benchmark for FedLLM. It offers a comprehensive testbed with four datasets: Fed-Aya (multilingual instruction tuning), Fed-WildChat (multi-turn chat instruction tuning), Fed-ChatbotIT (single-turn chat instruction tuning), and Fed-ChatbotPA (preference alignment). These datasets are naturally split by real-world user IDs across 38 to 747 clients, capturing realistic federated properties like cross-device data partitioning. The datasets exhibit diversity in languages, data quality, quantity, sequence lengths, and user preferences, mirroring real-world complexities. FedLLM-Bench integrates these datasets with 8 baseline methods and 6 evaluation metrics to facilitate method comparisons and exploration of new research directions.
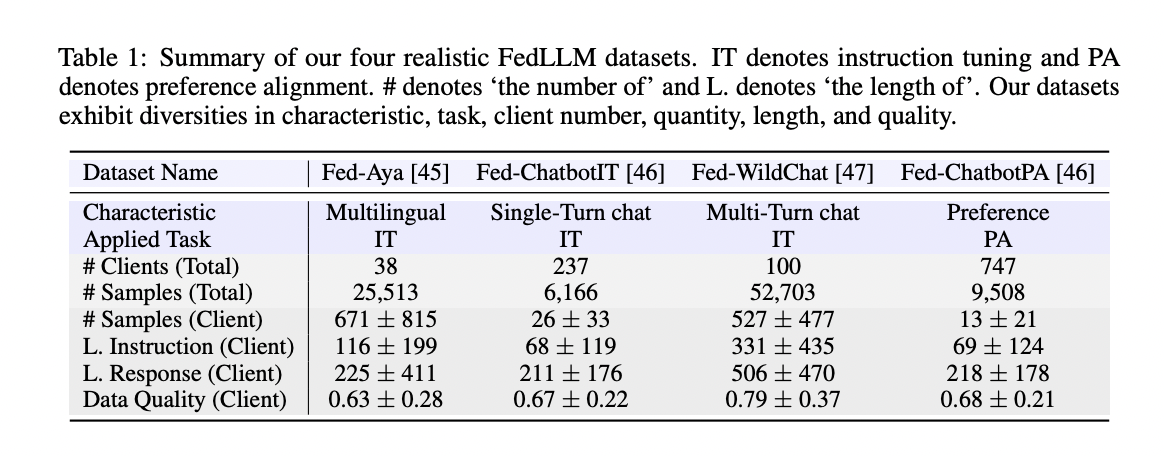
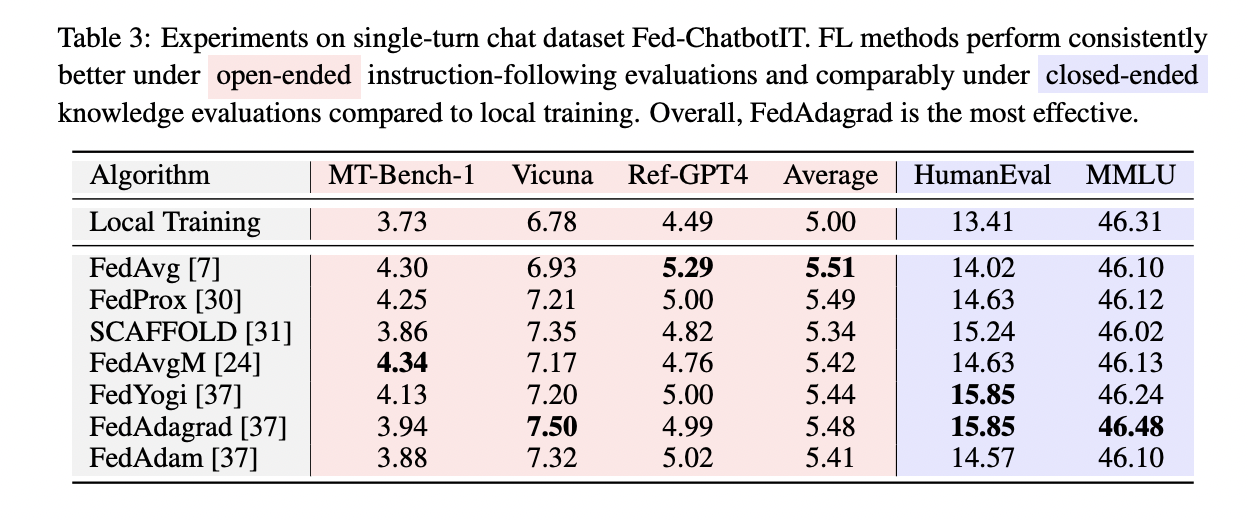
The FedLLM-Bench is introduced from four perspectives: training methods, datasets, dataset analysis, and evaluation metrics. For training methods, it covers federated instruction tuning and preference alignment tasks using parameter-efficient LoRA fine-tuning along with 8 baseline FL methods like FedAvg, FedProx, SCAFFOLD, FedAvgM, FedAdagrad, FedYogi, and FedAdam. The benchmark includes four diverse datasets: Fed-Aya (multilingual instruction tuning), Fed-ChatbotIT, Fed-WildChat, and Fed-ChatbotPA, capturing realistic properties like varied languages, quality, quantity, lengths, and user preferences. Extensive dataset analysis reveals inter/intra-dataset diversities in aspects like length, instructions, quality, embeddings, and quantity. The evaluation uses 6 metrics – 4 open-ended (MT-Bench, Vicuna bench, AdvBench, Ref-GPT4) and 2 close-ended (MMLU, HumanEval).
The benchmark evaluates the implemented methods across diverse datasets. On the multilingual Fed-Aya, most federated methods outperform local training on average, though no single method dominates all languages, highlighting opportunities for language personalization. For Fed-ChatbotIT, all federated approaches enhance instruction-following ability over local training without compromising general capabilities, with FedAdagrad performing best overall. On Fed-WildChat for single and multi-turn conversations, federated methods consistently surpass local training, with FedAvg proving the most effective for multi-turn. For Fed-ChatbotPA preference alignment, federated training improves instruction-following and safety compared to local, with FedAvgM, FedProx, SCAFFOLD, and FedAvg being top performers. Across datasets, federated learning demonstrates clear benefits over individual training by utilizing collaborative data.
In this study, researchers introduce FedLLM-Bench, the first realistic benchmark for FedLLM. The core contribution is a suite of four diverse datasets spanning instruction tuning and preference alignment tasks, exhibiting real-world properties like varied languages, data quality, quantity, instruction styles, sequence lengths, embeddings, and user preferences across 38 to 747 clients. Integrated with eight training methods, four training datasets, and six evaluation metrics, extensive experiments on FedLLM-Bench benchmark classical federated approaches and explore research directions like cross-lingual collaboration and differential privacy. By providing a comprehensive, practical testbed mirroring real-world complexities, FedLLM-Bench aims to reduce effort, enable fair comparisons, and propel progress in the emerging area of FedLLM. This timely benchmark can greatly benefit the research community working on collaborative, privacy-preserving training of large language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Benchmarking Federated Learning for Large Language Models with FedLLM-Bench appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]