


The advent of generative artificial intelligence (AI) marks a significant technological leap, enabling the creation of new text, images, videos, and other media by learning from vast datasets. However, this innovative capability brings forth substantial copyright concerns, as it may utilize and repurpose the creative works of original authors without consent.
This research addresses the potential for copyright infringement by generative AI technologies, which can produce outputs that might mimic and replace original human-made content. Such infringement risks undermine the economic rights of original content creators and pose legal challenges in creative industries.
Traditionally, approaches to mitigate these risks have involved altering the training mechanisms of AI models to lessen the chance of generating copyright-infringing outputs. These methods, however, often compromise the effectiveness of AI applications by excluding high-quality but copyrighted data from training sets.
The research team from Princeton University, Columbia University, Harvard University, and the University of Pennsylvania proposes a novel economic framework that utilizes principles from cooperative game theory to establish a fair royalty distribution system. This system assesses the contributions of individual copyright holders to AI-generated content based on the probabilistic nature of generative models. It employs the Shapley value, a method from game theory, to assign royalties fairly, ensuring each contributor is compensated according to their data’s utility in training the AI.
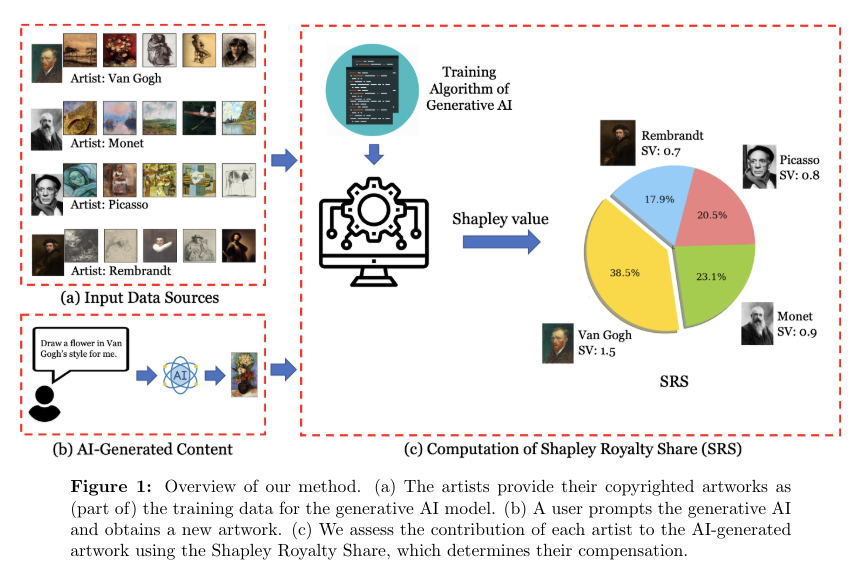
This framework is demonstrated through numerical experiments involving various data sets, including those from WikiArt and FlickrLogo-27. These experiments assess the model’s ability to allocate royalties accurately by analyzing the AI’s performance when generating content like artwork and logos, which rely on copyrighted and non-copyrighted training data. For example, in tests involving the WikiArt dataset, the utility scores calculated by the framework effectively mirrored the contributions of different artists’ styles to the AI-generated artwork.
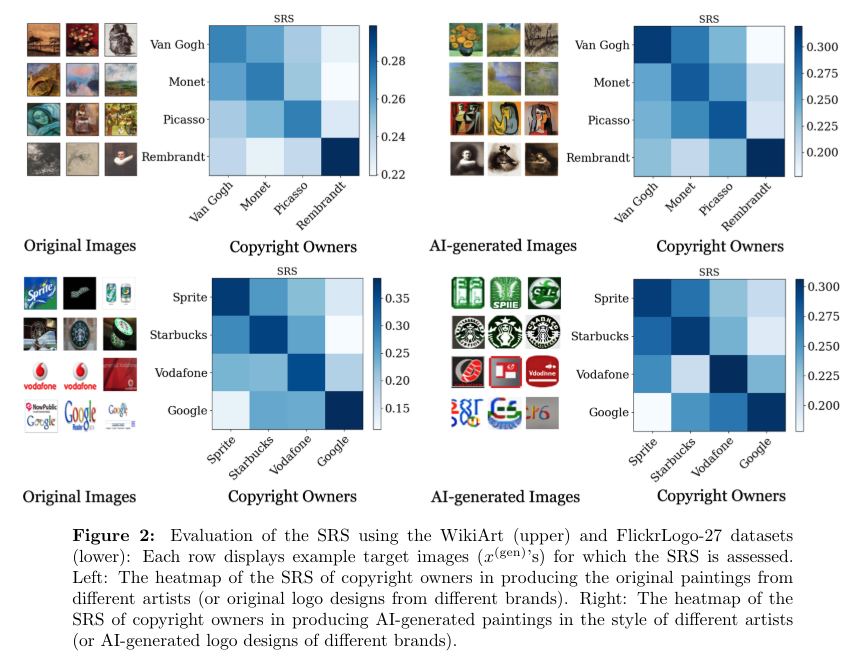
The research outlines how incorporating a broader range of training data without infringing on copyrights enhances the AI’s capability. For instance, when a generative model trained on a subset of data achieved a utility score of 0.85, it suggested a significant contribution by that data subset towards the generated content, compared to a baseline model.
The research also critically examines the complexities of implementing such an economic model in real-world scenarios, considering the computational challenges and the legal ambiguities surrounding copyright laws that affect generative AI. It acknowledges that while the proposed model aims to foster collaboration between AI developers and copyright owners, the dynamic nature of copyright laws and the diversity of data sources require a flexible and adaptable solution.

In conclusion, the research effectively addresses the pressing issue of copyright infringement in generative AI by proposing a sophisticated economic model grounded in cooperative game theory. Utilizing the Shapley value, the method quantitatively attributes fair compensation to copyright owners based on their contributions to the AI’s training data. Demonstrated through rigorous numerical experiments, the results affirm the model’s capability to distribute royalties equitably, aligning the interests of AI developers and copyright holders. This approach mitigates legal risks, and fosters continued innovation and collaboration in the burgeoning field of AI-driven content creation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Ongoing lawsuits against GenAI firms over possible use of #copyrighted data for training raise vital questions for our society.
How can we address the copyright challenges?
New research proposes a solution:
"An Economic Solution to Copyright Challenges of Generative AI" pic.twitter.com/ajwNqu48iY
— Weijie Su (@weijie444) April 25, 2024

The post Balancing Innovation and Rights: A Cooperative Game Theory Approach to Copyright Management in Generative AI Technologies appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]