


The quest to process lengthy documents with precision has been a formidable challenge. Generative transformer models have been at the forefront, dissecting and comprehending extensive texts. Their effectiveness wanes when faced with documents sprawling across tens of thousands of tokens, revealing a gap in the current methodologies. This limitation underscores the need to navigate the complexities of extensive texts without sacrificing accuracy or efficiency.
The recent breakthrough in augmenting pre-trained language models with recurrent memory has marked a significant leap forward. This method, diverging from traditional benchmarks that struggled beyond sequences of 104 elements, showcases an ability to tackle tasks involving sequences up to an astounding 107 elements. This advancement not only sets a new precedent for the input sequence size a neural network can process but also paves the way for models to delve into more intricate and realistic scenarios.
Researchers from AIRI Moscow, Neural Networks and Deep Learning Lab MIPT, and London Institute for Mathematical Sciences introduce BABILong, a pioneering benchmark meticulously crafted to evaluate NLP models’ prowess in dissecting long documents. By intricately weaving simple episodic facts within a corpus of book texts, BABILong creates a complex needle-in-a-haystack scenario. This benchmark tests models’ ability to sift through up to 10 million tokens, locating and leveraging pertinent information hidden within an ocean of data. This daunting task challenges even the most advanced models to demonstrate their capability to effectively process and understand long documents.
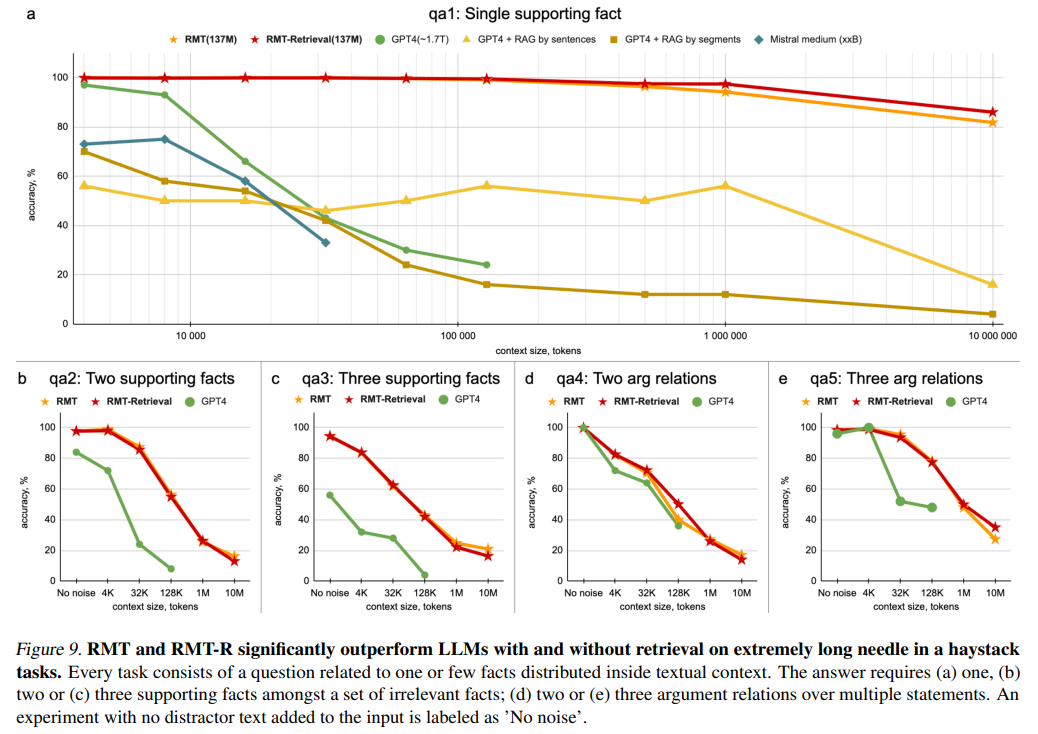
The evaluation of different models against the BABILong benchmark reveals a notable disparity in performance. When GPT-2, a smaller generative model, is fine-tuned with recurrent memory augmentations, it outshines its counterparts, including the more sophisticated GPT-4 and Retrieval-Augmented Generation (RAG) models. This fine-tuning enables GPT-2 to adeptly handle sequences extending up to 10 million tokens, showcasing unprecedented proficiency in processing long sequences.
This methodological innovation redefines the parameters of possibility within the domain. By integrating recurrent memory, these models can now engage with long documents in a manner previously deemed unfeasible. This progression holds profound implications for the future of NLP, potentially unlocking new avenues for research and application that were once beyond reach.
In conclusion, exploring and implementing recurrent memory augmentations for transformer models signify a pivotal development in NLP. The key takeaways from this advancement include:
- The introduction of BABILong, a new benchmark, addresses the critical need for tools that can rigorously evaluate the performance of NLP models on long documents.
- Fine-tuning GPT-2 with recurrent memory augmentations has proven to be a game-changer, dramatically enhancing the model’s ability to process and understand documents with up to 10 million tokens.
- This breakthrough showcases the potential of augmenting models with recurrent memory and illuminates the path forward for developing more sophisticated and capable NLP applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post BABILong: Revolutionizing Long Document Processing through Recurrent Memory Augmentation in NLP Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]