


Code generation is a field that aims to enhance software development processes by creating tools that can automatically generate, interpret, and debug code. These tools improve efficiency and reduce programming errors, which is crucial for modern software development. Advancements in this area have the potential to significantly impact how software is written, tested, and maintained.
The primary problem is creating high-quality, large-scale datasets for training language models in code generation. Traditional methods of dataset creation are costly and time-consuming, often relying on manual annotation or expensive closed-source models. This dependency limits the accessibility and scalability of developing powerful code generation tools, as manually annotating large datasets is both labor-intensive and economically demanding.
Current methods for creating code instruction datasets include SELF-INSTRUCT, EVOL-INSTRUCT, and OSS-INSTRUCT. These methods use strong teacher models to generate synthetic coding instructions or derive problems from open-source code snippets. However, these approaches are limited by their dependency on the teacher models, which can transfer correct and incorrect knowledge to student models. As a result, the performance of these student models is capped by the quality and accuracy of the teacher models, making it challenging to achieve breakthroughs in code generation capabilities.
Researchers from the University of Connecticut and AIGCode introduced a novel method called AIEV-INSTRUCT. This method creates a high-quality code dataset through an interactive process involving two agents—a questioner and a programmer—that simulate coding and testing dialogues. The method transitions from proprietary models to self-learning stages, reducing reliance on costly closed-source models. This innovative approach not only addresses the limitations of existing methods but also enhances the robustness and accuracy of the generated datasets.
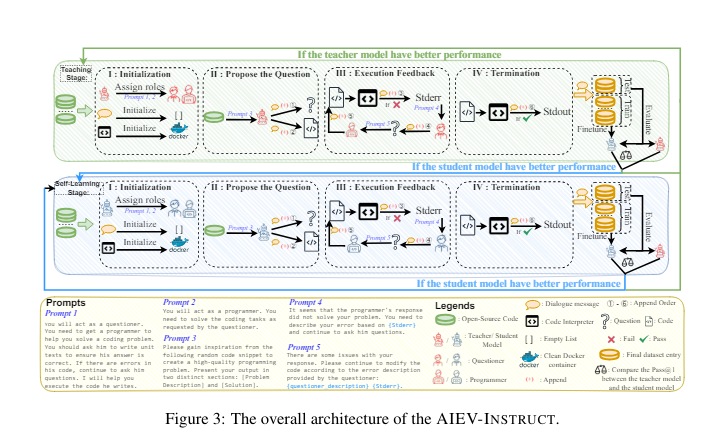
AIEV-INSTRUCT operates in two stages: the Teaching Stage and the Self-learning Stage. Initially, it uses a proprietary model to generate and validate code instructions. In the Teaching Stage, GPT-4 Turbo serves as the teacher model, guiding the generation of high-quality code snippets and ensuring their correctness through unit tests. The process involves multiple rounds of interaction between the questioner and programmer agents, with execution feedback used to refine the generated code continuously. Once the student model surpasses the teacher model in accuracy, it transitions to a self-learning stage where the student model autonomously generates and validates code. In the Self-learning Stage, the student model itself acts as both the questioner and programmer, iteratively improving its performance through self-generated dialogues and execution feedback. This process ensures the generated code’s accuracy and reduces dependency on expensive closed-source models.
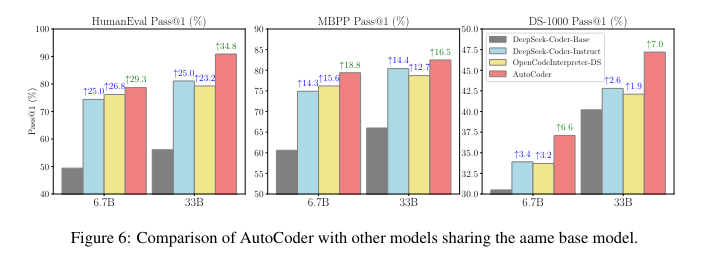
The performance of the proposed model, AutoCoder, trained with AIEV-INSTRUCT, is remarkable. AutoCoder achieved a pass rate of 90.9% on the HumanEval benchmark, surpassing top models like GPT-4 Turbo, which scored 90.2%. Moreover, AutoCoder demonstrated superior capabilities in code interpretation, allowing for the installation of external packages, unlike its predecessors, which were limited to built-in packages. This capability significantly enhances AutoCoder’s versatility and applicability in real-world coding scenarios. Furthermore, AutoCoder was tested on several datasets, including HumanEval+, MBPP, MBPP+, MultiPL-E, and DS-1000. It ranked first among all language models on the HumanEval Base Test and achieved top-five rankings on the other benchmarks. Specifically, AutoCoder-S, a smaller variant with 6.7 billion parameters, showed impressive results with pass rates of 78.7% on HumanEval and 79.4% on MBPP, highlighting its efficiency and accuracy even with fewer parameters.
In conclusion, the research introduces a significant advancement in code generation by proposing a cost-effective and accurate method for creating code instruction datasets. AutoCoder, utilizing the AIEV-INSTRUCT method, exhibits exceptional performance, surpassing existing models in key benchmarks. This innovation enhances the efficiency of code generation tasks and provides a scalable approach to improving language models in coding applications. The University of Connecticut and AIGCode contributions demonstrate the potential for substantial improvements in software development processes, making high-quality code generation tools more accessible and effective for developers worldwide.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post AutoCoder: The First Large Language Model to Surpass GPT-4 Turbo (April 2024) and GPT-4o in pass@1 on the Human Eval Benchmark Test (90.9% vs. 90.2%) appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]