


AI legal research and document drafting tools promise to enhance efficiency and accuracy in performing complex legal tasks. However, these tools need help with their reliability in producing accurate legal information. Lawyers increasingly use AI to augment their practice, from drafting contracts to analyzing discovery productions and conducting legal research. As of January 2024, 41 of the top 100 largest law firms in the United States have begun using some form of AI, with 35% of a broader sample of 384 firms reporting work with at least one generative AI provider. Despite these advancements, the adoption of AI in legal practice presents unprecedented ethical challenges, including concerns about client confidentiality, data protection, bias introduction, and the duty of lawyers to supervise their work product.
The primary issue addressed by the research is the occurrence of “hallucinations” in AI legal research tools. Hallucinations refer to instances where AI models generate false or misleading information. In the legal domain, such errors can have serious implications, given the high stakes involved in legal decisions and documentation. Previous studies have shown that general-purpose large language models (LLMs) hallucinate on legal queries between 58% and 82% of the time. This research seeks to address these gaps by evaluating AI-driven legal research tools offered by LexisNexis and Thomson Reuters, comparing their accuracy and incidence of hallucinations.
Existing AI legal tools, such as those from LexisNexis and Thomson Reuters, claim to mitigate hallucinations using retrieval-augmented generation (RAG) techniques. These tools are marketed to provide reliable legal citations and reduce the risk of false information. LexisNexis claims its tool delivers “100% hallucination-free linked legal citations,” while Thomson Reuters asserts that its system avoids hallucinations by relying on trusted content within Westlaw. However, these bold proclamations lack empirical evidence, and the term “hallucination” is often undefined in marketing materials. This study aims to systematically assess these claims by evaluating the performance of AI-driven legal research tools.
The Stanford and Yale University research team introduced a comprehensive empirical evaluation of AI-driven legal research tools. This evaluation involved a preregistered dataset designed to assess these tools’ performance systematically. The study focused on tools developed by LexisNexis and Thomson Reuters, comparing their accuracy and incidence of hallucinations. The methodology involved using a RAG system, which integrates the retrieval of relevant legal documents with AI-generated responses, aiming to ground the AI’s outputs in authoritative sources. The evaluation framework included detailed criteria for identifying and categorizing hallucinations based on factual correctness and citation accuracy.
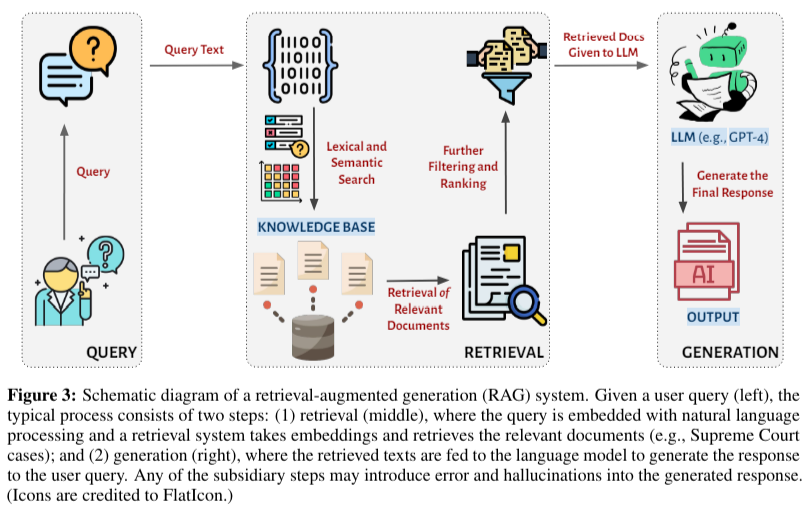
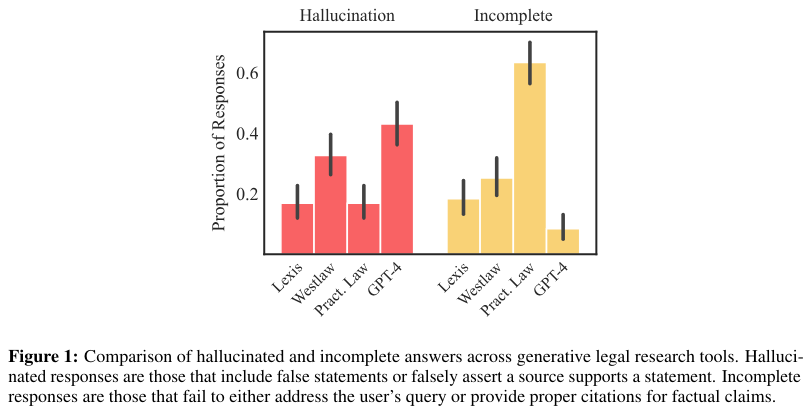
The proposed methodology involved using a RAG system. This system integrates the retrieval of relevant legal documents with AI-generated responses, aiming to ground the AI’s outputs in authoritative sources. The advantage of RAG is its ability to provide more detailed and accurate answers by drawing directly from retrieved texts. The study evaluated the performance of AI tools by LexisNexis, Thomson Reuters, and GPT-4, a general-purpose chatbot. The study’s results revealed that while the LexisNexis and Thomson Reuters AI tools reduced hallucinations compared to general-purpose chatbots like GPT-4, they still exhibited significant error rates. LexisNexis’ tool had a hallucination rate of 17%, while Thomson Reuters’ tools ranged between 17% and 33%. The study also documented variations in responsiveness and accuracy among the tools tested. LexisNexis’ tool was the highest-performing system, accurately answering 65% of queries. In contrast, Westlaw’s AI-assisted research was accurate 42% of the time but hallucinated nearly twice as often as the other legal tools tested.
The study’s results revealed that while the LexisNexis and Thomson Reuters AI tools reduced hallucinations compared to general-purpose chatbots like GPT-4, they still exhibited significant error rates. LexisNexis’ tool had a hallucination rate of 17%, while Thomson Reuters’ tool ranged between 17% and 33%. The study also documented variations in responsiveness and accuracy among the tools tested. LexisNexis’ tool was the highest-performing system, accurately answering 65% of queries. In contrast, Westlaw’s AI-assisted research was accurate 42% of the time but hallucinated nearly twice as often as the other legal tools tested.

In conclusion, the study highlights the persistent challenges of hallucinations in AI legal research tools. Despite advancements in techniques like RAG, these tools could be more foolproof and require careful supervision by legal professionals. The research underscores the need for continued improvement and rigorous evaluation to ensure the reliable integration of AI into legal practice. Legal professionals must remain vigilant in supervising and verifying AI outputs to mitigate the risks associated with hallucinations and ensure the responsible integration of AI in law.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Are AI-RAG Solutions Really Hallucination-Free? Researchers at Stanford University Assess the Reliability of AI in Legal Research: Hallucinations and Accuracy Challenges appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]