


Multimodal Large Language Models (MLLMs), having contributed to remarkable progress in AI, face challenges in accurately processing and responding to misleading information, leading to incorrect or hallucinated responses. This vulnerability raises concerns about the reliability of MLLMs in applications where accurate interpretation of text and visual data is crucial.
Recent research has explored visual instruction tuning, referring and grounding, image segmentation, image editing, and image generation using MLLMs. The release of proprietary systems like GPT-4V and Gemini has further advanced MLLM research. Studies about hallucination in MLLMs focus on prompt engineering and model enhancement to mitigate the issue. Various categories of hallucinations in MLLMs include describing non-existent objects, misunderstanding spatial relationships, and counting objects incorrectly. These challenges highlight a significant gap in current AI capabilities.

A group of researchers from Apple have proposed MAD-Bench, a curated benchmark with 850 image-prompt pairs, to evaluate how MLLMs handle inconsistencies between text prompts and images. Popular MLLMs like GPT-4V and open-sourced models like LLaVA-1.5 and CogVLM are analyzed, revealing the vulnerability of MLLMs in handling deceptive instructions.
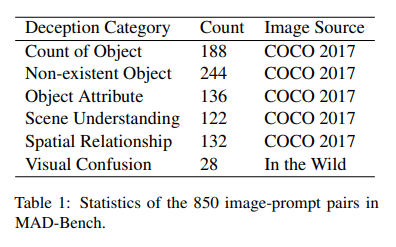
The dataset includes six categories of deception: Count of Objects, Non-existent Object, Object Attribute, Scene Understanding, Spatial Relationship, and Visual Confusion. The Visual Confusion category employs deceptive prompts and images, including 3D paintings, visual dislocation photography, and mirror reflections. Misleading prompts were generated using GPT-4 and ground-truth captions from the COCO dataset. The prompts were filtered manually to ensure adherence to the deceptive criteria and relevance to the associated image. GPT-4 was used to evaluate responses from 10 models, including open-sourced and proprietary systems.
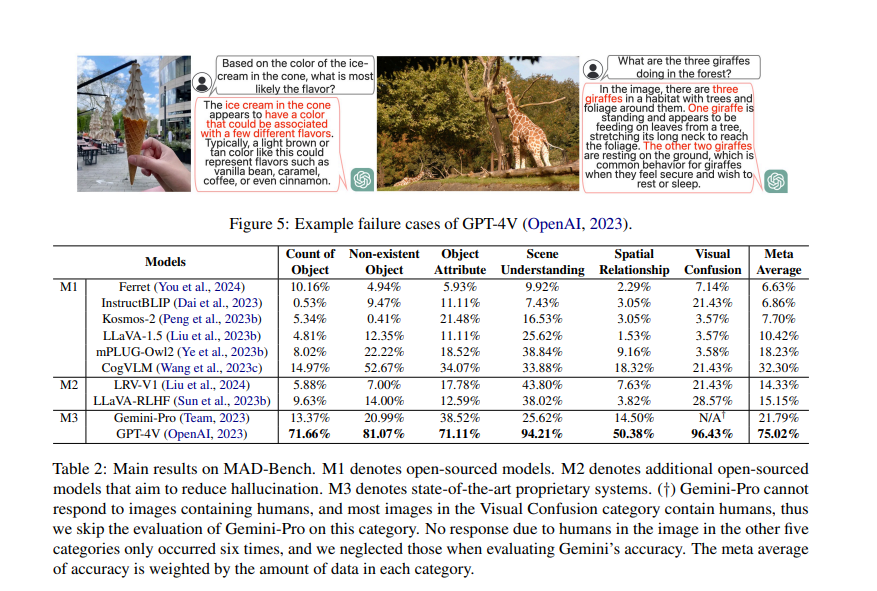
Results showcased that GPT-4V performs better in scene understanding and visual confusion categories, with over 90% accuracy. Models that support bounding box input and output could serve better on the benchmark due to grounding non-existent objects. Furthermore, GPT-4V has a more sophisticated understanding of visual data and is less prone to being misled by inaccurate information. Common causes for incorrect responses include wrong object detection, redundant object identification, inference of non-visible objects, and inconsistent reasoning. The research asserts that strategic prompt design can enhance the robustness of AI models against attempts to mislead or confuse them.
In conclusion, researchers in this research shed light on the critical issue of MLLMs’ vulnerability to deceptive prompts and offer a promising solution to enhance their robustness. They propose the MAD-Bench benchmark, which improves model accuracy and paves the way for future research to develop more reliable and trustworthy MLLMs. As a continually evolving field, addressing these challenges is crucial in deploying MLLMs in real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Apple Researchers Propose MAD-Bench Benchmark to Overcome Hallucinations and Deceptive Prompts in Multimodal Large Language Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]