


Virtual assistant technology aims to create seamless and intuitive human-device interactions. However, the need for a specific trigger phrase or button press to initiate a command interrupts the fluidity of natural dialogue. Recognizing this challenge, Apple researchers have embarked on a groundbreaking study to enhance the intuitiveness of these interactions. Their solution eliminates the need for trigger phrases, allowing users to interact with devices more spontaneously.
The heart of the challenge lies in accurately identifying when a spoken command is intended for the device amidst a stream of background noise and speech. This problem is markedly more complex than simple wake-word detection because it involves discerning the user’s intent without explicit cues. Previous attempts to address this issue have utilized acoustic signals and linguistic information. However, these methods often falter in noisy environments or ambiguous speech scenarios, which could be clearer, highlighting a gap that this new research aims to bridge.
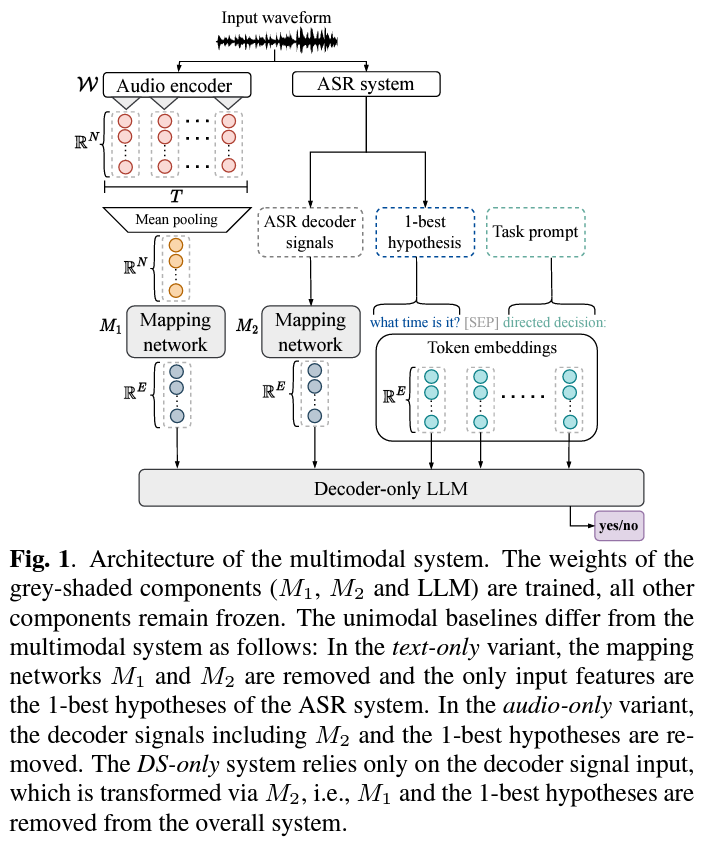
Apple’s research team introduces an innovative multimodal approach that leverages the synergy between acoustic data, linguistic cues, and outputs from automatic speech recognition (ASR) systems. This method’s core is using a large language model (LLM), which, due to its state-of-the-art text comprehension capabilities, can integrate diverse types of data to improve the accuracy of detecting device-directed speech. This approach utilizes the individual strengths of each input type and explores how their combination can offer a more nuanced understanding of user intent.
From a technical standpoint, the researchers’ methodology involves training classifiers using purely acoustic information extracted from audio waveforms. The decoder outputs of an ASR system, including hypotheses and lexical features, are then used as inputs to the LLM. The final step merges these acoustic and lexical features with ASR decoder signals into a multimodal system that inputs into an LLM, creating a robust framework for understanding and categorizing speech directed at a device.
The efficacy of this multimodal system is demonstrated through its performance metrics, which show significant improvements over traditional models. Specifically, the system achieves equal error rate (EER) reductions of up to 39% and 61% over text-only and audio-only models, respectively. Furthermore, by increasing the size of the LLM and applying low-rank adaptation techniques, the research team pushed these EER reductions even further, up to 18% on their dataset.
Apple’s groundbreaking research paves the way for more natural interactions with virtual assistants and sets a new benchmark for the field. By achieving an EER of 7.95% with the Whisper audio encoder and 7.45% with the CLAP backbone, the research showcases the potential of combining text, audio, and decoder signals from an ASR system. These results signify a leap towards the realization of virtual assistants that can understand and respond to user commands without the need for explicit trigger phrases, moving closer to a future where technology understands us just as well as we know it.
Apple’s research has resulted in significant improvements in human-device interaction. By combining the capabilities of multimodal information and advanced processing powered by LLMs, the research team has paved the way for the next generation of virtual assistants. This technology aims to make our interactions with devices more intuitive, similar to human-to-human communication. It has the potential to change our relationship with technology fundamentally.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post Apple Researchers Propose a Multimodal AI Approach to Device-Directed Speech Detection with Large Language Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]