


Current methods for aligning LLMs often match the general public’s preferences, assuming this is ideal. However, this overlooks the diverse and nuanced nature of individual preferences, which are difficult to scale due to the need for extensive data collection and model training for each person. Techniques like RLHF and instruction fine-tuning help align LLMs with broad human values such as helpfulness and harmlessness. Yet, this approach needs to address conflicting individual preferences, leading to annotation disagreements and undesirable model traits like verbosity.
KAIST AI and Carnegie Mellon University researchers have developed a new paradigm where users specify their values in system messages to align LLMs with individual preferences better. Traditional LLMs, trained with uniform messages like “You are a helpful assistant,” struggle to adapt to diverse system messages. They created the MULTIFACETED COLLECTION, a dataset with 192k unique system messages and 65k instructions to address this. Training a 7B LLM named JANUS on this dataset, they tested it against various benchmarks, achieving high performance and demonstrating that diverse system message training enhances alignment with individual and general public preferences. Their work is available on GitHub.
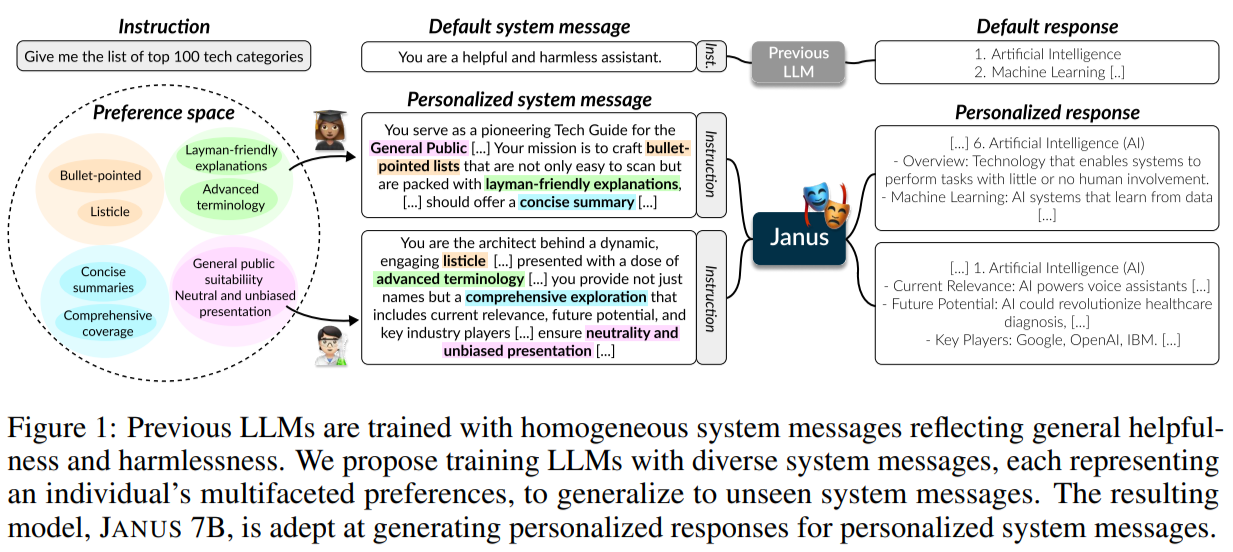
Aligning LLMs to diverse human preferences is crucial since individuals have varying values for the same task. Most research uses the RLHF pipeline, creating customized reward functions to reflect diverse perspectives better and reduce annotation disagreements. Some studies focus on learning multiple preference distributions or training separate models for user preferences. While these methods often involve impractical re-training, the proposed approach trains an LLM to adapt to explicitly stated preferences during test time. System messages, used to provide context and guide LLM behavior, have been shown to improve performance when diversified, but previous research has limited their scope. This work scales system messages to better align with user preferences.
Existing alignment datasets generally reflect broad preferences like helpfulness and harmlessness. The goal is to create a dataset capturing more specific preferences, such as “code-centric style” or “ensuring code ethics” for coding solutions. Preferences are detailed textual descriptions of desirable qualities in responses. Two requirements for a model to reflect diverse human preferences are multifacetedness and explicitness. A hierarchical preference augmentation strategy ensures a variety of preference facets. Multifaceted preferences are included in model inputs via system messages. Data construction involves selecting 65k instructions, generating 192k system messages, and crafting gold-standard responses using GPT-4 Turbo. Models are trained using several methods, including instruction tuning and preference optimization.
Benchmarks for evaluating the JANUS model include multifacetedness, helpfulness, and harmlessness. The MULTIFACETED BENCH enhances five existing benchmarks to assess context-specific nuances. Helpfulness is evaluated using Alpaca Eval 2.0, MT-Bench, and Arena Hard Auto v0.1, while harmlessness is assessed with RealToxicityPrompts. Baselines include various pre-trained, instruction-tuned, and preference-optimized models. Evaluations involve human and LLM assessments, showing that JANUS excels in generating personalized responses, maintaining helpfulness, and ensuring low toxicity. These results demonstrate JANUS’s ability to adapt to diverse preferences and maintain alignment with general helpful values without compromising safety.
In conclusion, several ablation studies reveal JANUS’s robust performance, both with and without system messages. JANUS’s multifaceted capabilities allow it to generate quality responses regardless of context. Incorporating multifaceted system messages during training enhances performance in both multifacetedness and helpfulness. Training without system messages, however, poses challenges in capturing human preferences effectively. JANUS can also serve as a personalized reward model, improving performance on MULTIFACETED BENCH through best-of-n sampling. The method aligns LLMs with diverse user preferences using a unique system message protocol and the MULTIFACETED COLLECTION dataset, ensuring high performance and adaptability without continual retraining.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Aligning Large Language Models with Diverse User Preferences Using Multifaceted System Messages: The JANUS Approach appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]