


In artificial intelligence, integrating large language models (LLMs) and speech-to-speech translation (S2ST) systems has led to significant breakthroughs. Two recent studies shed light on these advancements: one focusing on a novel attack method against LLMs and the other on a cutting-edge S2ST system. Let’s synthesize the findings from these research papers to highlight the progress and potential implications of AI-driven language processing.
Semantic Membership Inference Attack (SMIA)
Membership Inference Attacks (MIAs) are designed to determine whether a specific data point was included in the training set of a target model. The research conducted by Mozaffari and Marathe introduces the Semantic Membership Inference Attack (SMIA). This novel approach enhances MIA performance by leveraging the semantic content of inputs and their perturbations. Unlike traditional MIAs, which focus on exact sequence memorization, SMIA considers LLMs’ nuanced semantic memorization capabilities.
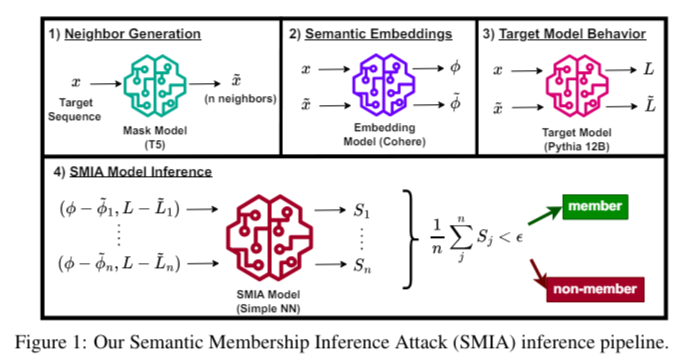
Key Innovations:
- Neighbor Generation: The target sequence is perturbed multiple times using a masking model like T5, creating a dataset of semantic neighbors.
- Semantic Embedding Calculation: The semantic embeddings of the input text and its neighbors are computed using an embedding model such as Cohere.
- Loss Calculation and Membership Probability Estimation: The target model’s behavior on the original and perturbed inputs is analyzed using a trained neural network to estimate membership probabilities.
The evaluation of models like Pythia and GPT-Neo using the Wikipedia dataset demonstrates that SMIA significantly outperforms existing MIAs. For instance, SMIA achieves an AUC-ROC of 67.39% on Pythia-12B, compared to 58.90% by the second-best attack. This improvement underscores the effectiveness of incorporating semantic analysis in MIA methodologies.
Diffusion Synthesizer for Efficient Multilingual Speech-to-Speech Translation
Hirschkind et al.’s study introduces DiffuseST, a direct speech-to-speech translation system capable of preserving the input speaker’s voice while translating from multiple source languages into English. This system incorporates a novel diffusion-based synthesizer, outperforming traditional Tacotron-based synthesizers regarding audio quality and latency.
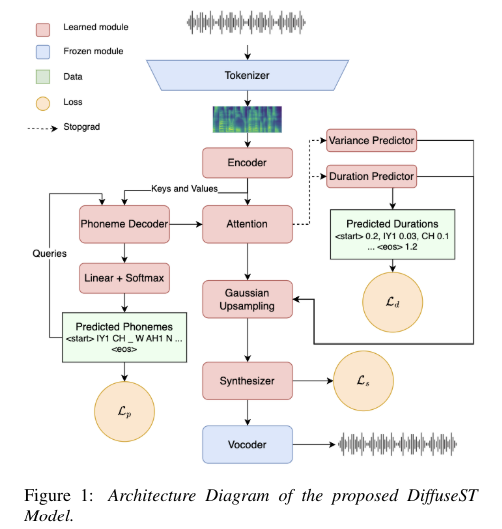
Main Contributions:
- Zero-Shot Speaker Preservation: DiffuseST can preserve the speaker’s voice characteristics without requiring extensive parallel data, thanks to pretraining on diverse voices.
- Low Latency: Despite having a higher parameter count, the diffusion synthesizer allows the entire model to run more than five times faster than in real time, making it suitable for streaming applications.
- Improved Audio Quality: Compared to the baseline, the diffusion synthesizer enhances Mean Opinion Score (MOS) and Perceptual Evaluation of Speech Quality (PESQ) metrics by 23% and speaker similarity by 5%.
System Architecture:
- Tokenizer and Acoustic Encoder: Converts waveform to Mel Spectrogram and encodes it using a pre-trained WhisperSmall encoder.
- Phoneme Decoder and Duration Prediction: Predicts phonemes and their durations using a transformer decoder with rotary embeddings.
- Diffusion Synthesizer: This synthesizer generates high-quality audio while preserving the input speaker’s voice, leveraging a conditional flow matching the diffusion objective.
The system was evaluated on public datasets, including The People’s Speech, SpeechMatrix, LibriSpeech Multilingual, and CVSS-T. The results indicate that DiffuseST achieves competitive BLEU scores, significantly improving audio quality and speaker preservation.
Implications, Future Directions, and Conclusion
The advancements in SMIA and DiffuseST reflect the growing sophistication in AI-driven language and speech processing. The SMIA approach highlights the importance of semantic understanding in protecting privacy and ensuring data integrity in LLMs. Meanwhile, DiffuseST’s innovative use of diffusion models sets a new standard for real-time, high-quality speech translation systems.
Future research could explore integrating SMIA techniques to enhance privacy and security in S2ST systems. Additionally, the continued refinement of diffusion synthesizers could lead to even more efficient and versatile translation models, paving the way for seamless multilingual communication.
In conclusion, the combined insights from these studies demonstrate the potential of advanced AI methodologies to revolutionize language and speech processing, offering enhanced performance and critical privacy safeguards.
Sources
- https://arxiv.org/pdf/2406.10218
- https://arxiv.org/pdf/2406.10223
The post Advancements in Multilingual Speech-to-Speech Translation and Membership Inference Attacks: A Comprehensive Review appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]