


Large language models (LLMs) now support very long context windows, but the quadratic complexity of standard attention results in significantly prolonged Time-to-First-Token (TTFT) latency. Existing methods to tackle this complexity require extra pretraining or finetuning and often compromise model accuracy. The quadratic nature of the vanilla attention mechanism in these models significantly increases computational time, making real-time interactions challenging. Current solutions usually compromise model accuracy or require additional pretraining, which is often impractical.
Current methods to mitigate the quadratic complexity of attention in LLMs include sparse attention, low-rank matrices, unified sparse and low-rank attention, recurrent states, and external memory. These approaches aim to approximate dense attention or manage memory more efficiently. However, they often necessitate additional pretraining or finetuning, leading to accuracy losses and impracticality for pre-trained models.
A team of researchers from China proposed SampleAttention, an adaptive structured sparse attention mechanism. SampleAttention leverages significant sparse patterns observed in attention mechanisms to capture essential information with minimal overhead. It attends to a fixed percentage of adjacent tokens to handle local window patterns. It employs a two-stage query-guided key-value (KV) filtering approach to capture column stripe patterns. This method offers near-lossless sparse attention, seamlessly integrating into off-the-shelf LLMs without compromising accuracy.
SampleAttention addresses the high TTFT latency by dynamically capturing head-specific sparse patterns during runtime with low overhead. The method focuses on two primary sparse patterns: local window patterns and column stripe patterns. Local window patterns are handled by attending to a fixed percentage of adjacent tokens, ensuring that important local dependencies are captured efficiently. Column stripe patterns are managed through a two-stage query-guided KV filtering approach, which adaptively selects a minimal set of key-values to maintain low computational overhead.
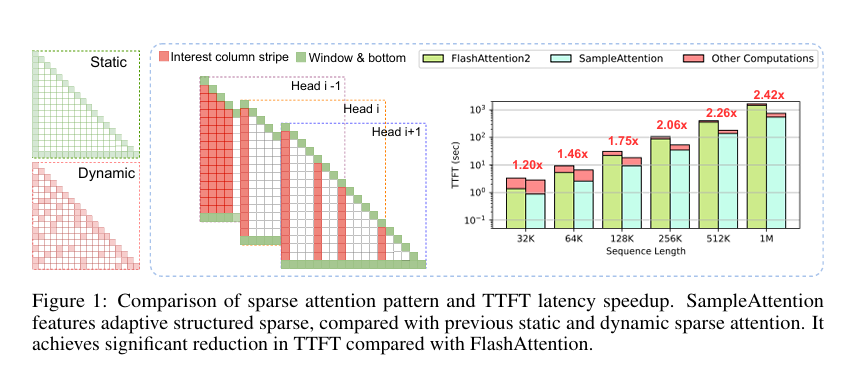
The proposed method was evaluated on widely used LLM variants like ChatGLM2-6B and internLM2-7B, demonstrating its effectiveness in long-context scenarios. SampleAttention showed significant performance improvements, reducing TTFT by up to 2.42 times compared to FlashAttention. The evaluations included tasks such as LongBench, BABILong, and the “Needle in a Haystack” stress test, where SampleAttention maintained nearly no accuracy loss while significantly accelerating attention operations.
This research effectively addresses the problem of high TTFT latency in LLMs with long context windows by introducing SampleAttention. This adaptive structured sparse attention method reduces computational overhead while maintaining accuracy, providing a practical solution for integrating into pre-trained models. The combination of local window and column stripe patterns ensures efficient handling of essential information, making SampleAttention a promising advancement for real-time applications of LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Accelerating LLM Inference: Introducing SampleAttention for Efficient Long Context Processing appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]