


Large language models (LLMs) have gained significant capabilities, reaching GPT-4 level performance. However, deploying these models for applications requiring extensive context, such as repository-level coding and hour-long video understanding, poses substantial challenges. These tasks demand input contexts ranging from 100K to 10M tokens, a significant leap from the standard 4K token limit. Researchers are grappling with an ambitious goal: How can the deployment of 1M context production-level transformers be made as cost-effective as their 4K counterparts? The primary obstacle in serving long-context transformers is the size of the KV cache. For instance, a 30+B parameter model with 100K context requires a staggering 22.8GB of KV cache, compared to just 0.91GB for 4K context, highlighting the exponential increase in memory requirements as context length grows.
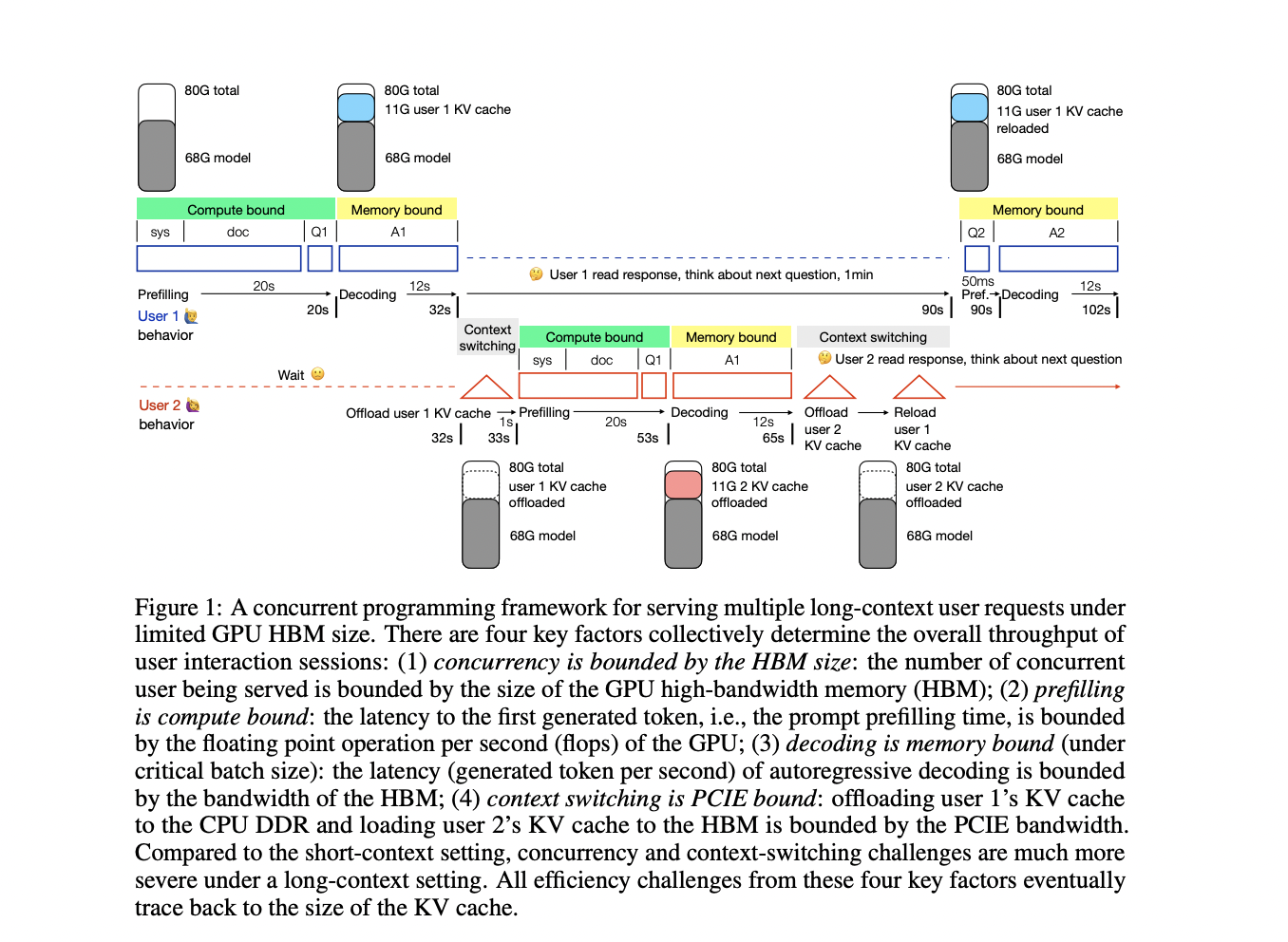
To overcome the challenges of deploying long-context transformers, the University of Edinburgh researcher has developed a concurrent programming framework for quantitative analysis of efficiency issues when serving multiple long-context requests under limited GPU high-bandwidth memory (HBM). This framework focuses on a 34B GPT-3.5 level model with a 50K context on an A100 NVLink GPU as a representative example. The analysis reveals four key deployment challenges stemming from the large KV cache: extended prefilling time and memory usage for long inputs, restricted concurrent user capacity due to HBM occupation, increased decoding latency from frequent KV cache access, and significant context switching latency when swapping KV cache between HBM and DDR memory. This comprehensive framework enables researchers to evaluate existing solutions and explore potential combinations for developing end-to-end systems that can efficiently handle long-context language models.
The study focuses on compressing the KV cache across four dimensions: layer, head, token, and hidden. Researchers hypothesize that some tasks may not require full-depth computation for the layer dimension, allowing for layer skipping during prefilling. This approach could potentially reduce the KV cache to just one layer, achieving a 1/60 compression ratio. In the head dimension, studies suggest that certain heads specialize in retrieval and long-context capabilities. By retaining only these crucial heads and pruning others, significant compression can be achieved. For instance, some research indicates that as few as 20 out of 1024 heads might be sufficient for retrieval tasks.
The token dimension compression is based on the hypothesis that if a token’s information can be inferred from its context, it can be compressed by dropping or merging it with neighboring tokens. However, this dimension appears less compressible than layers or heads, with most works showing less than 50% compression ratio. The hidden dimension, already small at 128, has seen limited exploration beyond quantization techniques. Researchers suggest that applying dimension reduction techniques like LoRA to the KV cache might yield further improvements. The framework also considers the relative cost between prefilling and decoding, noting that as models grow larger and context lengths increase, the cost shifts from decoding to prefilling, emphasizing the need for optimizing both aspects for efficient long-context deployment.
The research presents a comprehensive analysis of challenges in deploying long-context transformers, aiming to make 1M context serving as cost-effective as 4K. This goal would democratize advanced AI applications like video understanding and generative agents. The study introduces a concurrent programming framework that breaks down user interaction throughput into four key metrics: concurrency, prefilling, decoding, and context switching. By examining how various factors impact these metrics and reviewing existing optimization efforts, the research highlights significant opportunities for integrating current approaches to developing robust end-to-end long-context serving systems. This work lays the groundwork for full-stack optimization of long-context inference.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post A Concurrent Programming Framework for Quantitative Analysis of Efficiency Issues When Serving Multiple Long-Context Requests Under Limited GPU High-Bandwidth Memory (HBM) Regime appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]