


In large language models (LLMs), choosing the right inference backend for serving LLMs is important. The performance and efficiency of these backends directly impact user experience and operational costs. A recent benchmark study conducted by the BentoML engineering team offers valuable insights into the performance of various inference backends, specifically focusing on vLLM, LMDeploy, MLC-LLM, TensorRT-LLM, and Hugging Face TGI (Text Generation Inference). This study, executed on the Llama 3 8B and 70B 4-bit quantization models on an A100 80GB GPU instance, comprehensively analyzes their serving capabilities under different inference loads.
Key Metrics
The benchmark study utilized two primary metrics to evaluate the performance of these backends:
- Time to First Token (TTFT): This measures the latency from when a request is sent to when the first token is generated. Lower TTFT is crucial for applications requiring immediate feedback, such as interactive chatbots, as it significantly enhances perceived performance and user satisfaction.
- Token Generation Rate: This assesses how many tokens the model generates per second during decoding. A higher token generation rate indicates the model’s capacity to handle high loads efficiently, making it suitable for environments with multiple concurrent requests.
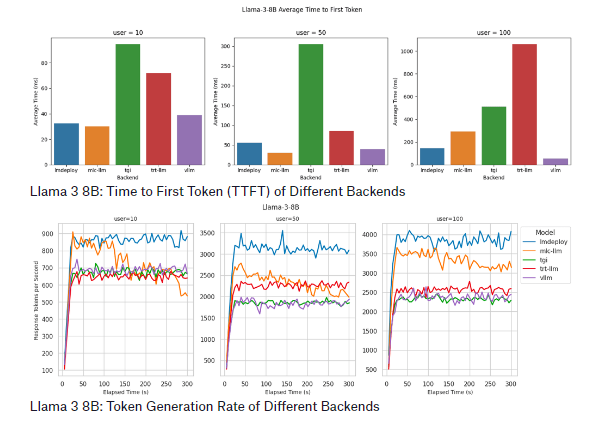
Findings for Llama 3 8B
The Llama 3 8B model was tested under three levels of concurrent users (10, 50, and 100). The key findings are as follows:
- LMDeploy: This backend delivered the best decoding performance, generating up to 4000 tokens per second for 100 users. It also achieved the best TTFT with ten users, maintaining low TTFT even as the number of users increased.
- MLC-LLM: This backend achieved a slightly lower token generation rate of about 3500 tokens per second for 100 users. However, its performance degraded to around 3100 tokens per second after five minutes of benchmarking. TTFT also degraded significantly at 100 users.
- vLLM: Although vLLM excelled in maintaining the lowest TTFT across all user levels, its token generation rate was less optimal than LMDeploy and MLC-LLM, ranging from 2300 to 2500 tokens per second.
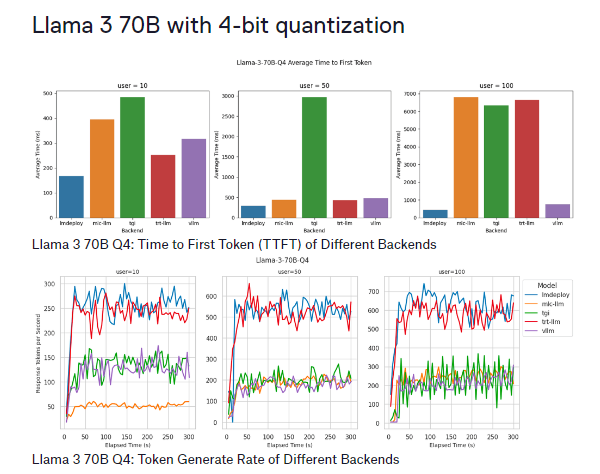
Findings for Llama 3 70B with 4-bit Quantization
For the Llama 3 70B model, the performance varied:
- LMDeploy: It provided the highest token generation rate, up to 700 tokens per second for 100 users, and maintained the lowest TTFT across all concurrency levels.
- TensorRT-LLM: This backend showed token generation rates similar to LMDeploy but experienced significant TTFT increases (over 6 seconds) when concurrent users reached 100.
- vLLM: Consistently low TTFT was observed, but the token generation rate lagged due to a lack of optimization for quantized models.
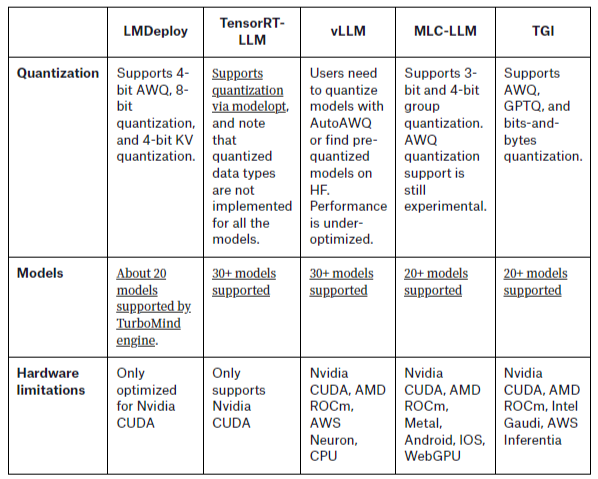
Beyond Performance: Other Considerations
Beyond performance, other factors influence the choice of inference backend:
- Quantization Support: Different backends support various quantization techniques, affecting memory usage and inference speed.
- Hardware Compatibility: While some backends are optimized for Nvidia CUDA, others support a broader range of hardware, including AMD ROCm and WebGPU.
- Developer Experience: The ease of use, availability of stable releases, and comprehensive documentation are critical for rapid development and deployment. For instance, LMDeploy and vLLM offer stable releases and extensive documentation, while MLC-LLM requires an understanding of model compilation steps.
Conclusion
This benchmark study highlights that LMDeploy consistently delivers superior performance in TTFT and token generation rates, making it a strong choice for high-load scenarios. vLLM is notable for maintaining low latency, which is crucial for applications needing quick response times. While showing potential, MLC-LLM needs further optimization to handle extended stress testing effectively.
These insights give developers and enterprises looking to deploy LLMs a foundation for making informed decisions about which inference backend best suits their needs. Integrating these backends with platforms like BentoML and BentoCloud can further streamline the deployment process, ensuring optimal performance and scalability.
The post A Comprehensive Study by BentoML on Benchmarking LLM Inference Backends: Performance Analysis of vLLM, LMDeploy, MLC-LLM, TensorRT-LLM, and TGI appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #TechNews #Technology [Source: AI Techpark]