


The surge in powerful Transformer-based language models (LMs) and their widespread use highlights the need for research into their inner workings. Understanding these mechanisms in advanced AI systems is crucial for ensuring their safety, and fairness, and minimizing biases and errors, especially in critical contexts. Consequently, there’s been a notable uptick in research within the natural language processing (NLP) community, specifically targeting interpretability in language models, yielding fresh insights into their internal operations.
Existing surveys detail a range of techniques utilized in Explainable AI analyses and their applications within NLP. While earlier surveys predominantly centred on encoder-based models such as BERT, the emergence of decoder-only Transformers spurred advancements in analyzing these potent generative models. Simultaneously, research has explored trends in interpretability and their connections to AI safety, highlighting the evolving landscape of interpretability studies in the NLP domain.
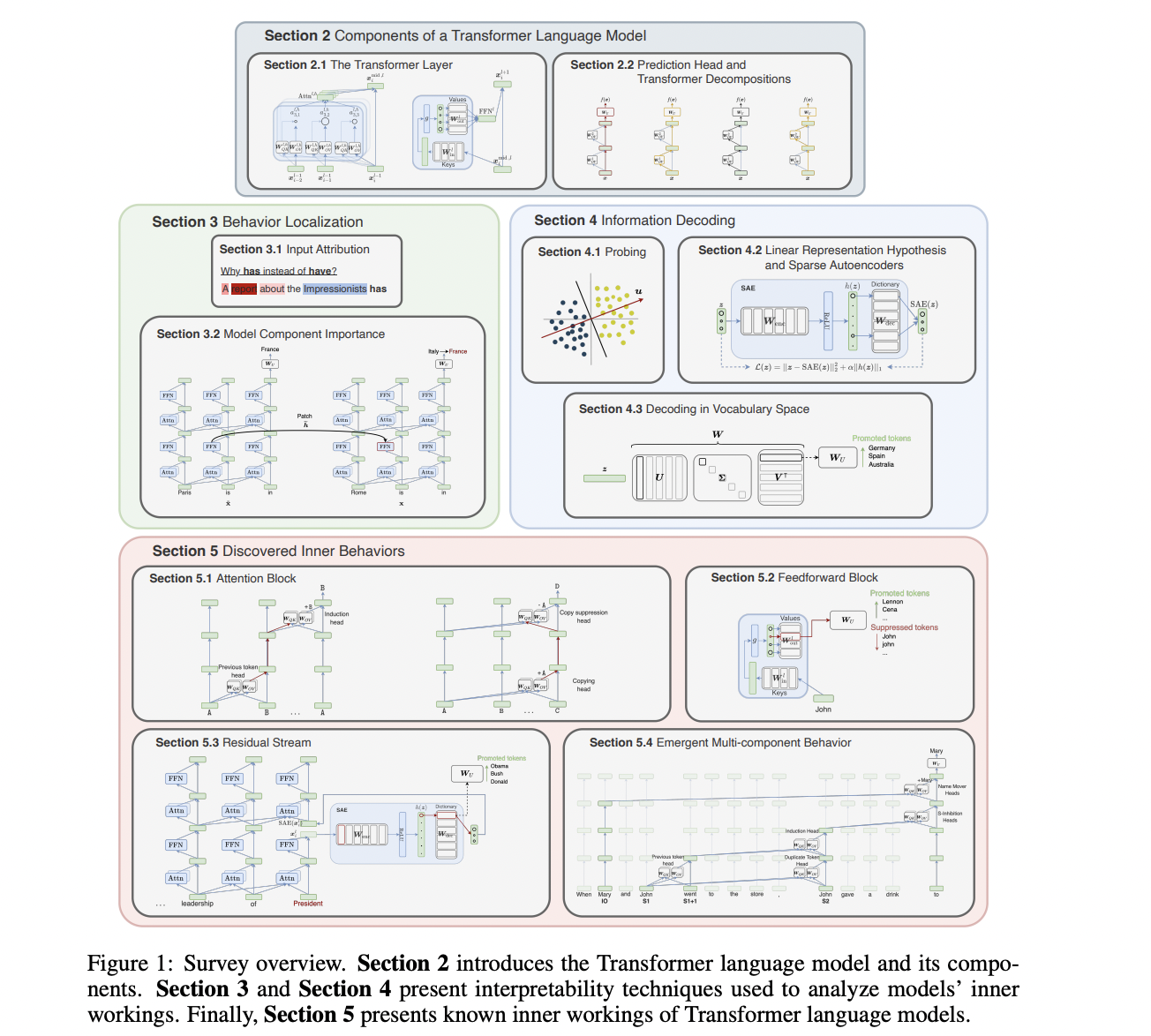
Researchers from Universitat Politècnica de Catalunya, CLCG, University of Groningen, and FAIR, Meta present the study which offers a thorough technical overview of techniques employed in LM interpretability research, emphasizing insights garnered from models’ internal operations and establishing connections across interpretability research domains. Employing a unified notation, it introduces model components, interpretability methods, and insights from surveyed works, elucidating the rationale behind specific method designs. The LM interpretability approaches discussed are categorized based on two dimensions: localizing inputs or model components for predictions and decoding information within learned representations. Also, they provide an extensive list of insights into Transformer-based LM workings and outline useful tools for conducting interpretability analyses on these models.
Researchers present two different types of methods that allow localizing model behavior: input attribution and model component attribution. Input attribution methods estimate token importance using gradients or perturbations. Context mixing alternatives to attention weights provide insights into token-wise attributions. Logit attribution measures component contributions, while causal interventions view computations as causal models. Circuit analysis identifies interacting components, with recent advances automating circuit discovery and abstracting causal relationships. These methods offer valuable insights into language model workings, aiding model improvement and interpretability efforts. Early investigations into Transformer LMs revealed sparse capabilities, where even removing a significant portion of attention heads may not harm performance. Direct Logit Attributions (DLA) measure the contribution of each LM component to token prediction, facilitating dissecting model behavior. Causal Interventions view LM computations as causal models, intervening to gauge component effects on predictions. Circuit Analysis identifies interacting components, aiding in understanding LM workings, albeit with challenges such as input template design and compensatory behavior. Recent approaches automate circuit discovery, enhancing interpretability.
They explore methods to decode information in neural network models, especially in natural language processing. Probing uses supervised models to predict input properties from intermediate representations. Linear interventions erase or manipulate features to understand their importance or steer model outputs. Sparse Autoencoders disentangle features in models with superposition, promoting interpretable representations. Gated SAEs improve feature detection in SAEs. Decoding in vocabulary space and maximally-activating inputs provide insights into model behavior. Natural language explanations from LMs offer plausible justifications for predictions but may lack faithfulness to the model’s inner workings. They also provided an overview of several open-source software libraries (Captum, a library in the Pytorch ecosystem providing access to several gradient and perturbation-based input attribution methods for any Pytorch-based model) that were introduced to facilitate interpretability studies on Transformer-based LMs.
In conclusion, this comprehensive study underscores the imperative of understanding Transformer-based language models’ inner workings to ensure their safety, fairness, and mitigating biases. Through a detailed examination of interpretability techniques and insights gained from model analyses, the research contributes significantly to the evolving landscape of AI interpretability. By categorizing interpretability methods and showcasing their practical applications, the study advances the field’s understanding and facilitates ongoing efforts to improve model transparency and interoperability.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
The post Deciphering Transformer Language Models: Advances in Interpretability Research appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #Technology [Source: AI Techpark]