


Language models built on Large Language models (LLMs) have been developed for multiple applications, followed by new advancements in enhancing LLMs. However, LLMs lack adaption and personalization to a particular user and task. Users often provide feedback to LLM-based agents through user edits and editing their responses before the final use. In contrast, standard fine-tuning feedback, like comparison-based preference feedback in RLHF, is collected by giving model responses to annotators and asking them to rank, making such feedback a costly option for enhancing alignment.
Researchers explored interactive learning of language agents depending on user edits to the agent’s output. In tasks like writing assistants, the user and language agent interact with each other to generate a response based on a context and edit the agent response to make it more personal and enhance correctness based on their latent preference. Moreover, researchers in this paper introduced PRELUDE, a learning framework to conduct PREference Learning from User’s Direct Edits presenting details of the user’s latent preference. However, user preference can be complicated and subtle, and changes based on context create a learning problem.
A team of researchers from Cornell University’s Department of Computer Science and Microsoft Research New York introduced CIPHER, a powerful algorithm designed to address the complexities of user preferences. CIPHER employs a large language model to deduce user preferences within a specific context based on user edits. It retrieves inferred preferences from the nearest historical contexts and combines them to generate responses. When compared to algorithms that directly retrieve user edits without learning descriptive preferences or those that learn context-independent preferences, CIPHER excels, achieving the lowest edit distance cost.
GPT-4 has been used as base LLM for CIPHER and all baselines by researchers. Also, no fine-tuning is done on GPT-4, and no extra parameters are added to the model. A GPT-4 agent guided by prompts is used for all methods utilizing a single prompt and basic decoding to generate responses. Moreover, CIPHER and the baselines are extended to more complex language agents. CIPHER is evaluated against baselines that either don’t learn anything, only learn preferences not influenced by context, or use methods that utilize past user edits to generate responses without learning preferences.
CIPHER achieves the smallest edit distance cost, reducing edits by 31% in the summarization task and 73% in the email writing task. This is achieved by retrieving five preferences (k=5) and combining them. Moreover, CIPHER achieves the highest preference accuracy, showing its potential to learn preferences that align with ground truth preference compared to other document sources. Also, it outperforms ICL-edit and Continual LPI baselines regarding cost reduction. CIPHER is cost-effective, highly efficient, and easier to understand than other baseline methods.
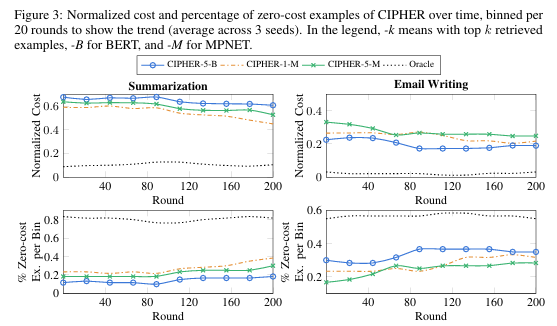
In summary, researchers introduce the PRELUDE framework, which concentrates on learning preferences from user edit data and generating an agent response accordingly. However, to handle the user compilations, they introduced CIPHER, an effective retrieval-based algorithm that infers user preference by querying the LLM, retrieving relevant examples in the past, and aggregating induced preferences to generate context-specific responses. Compared to other baseline methods, CIPHER outperforms them in cost reduction.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
The post CIPHER: An Effective Retrieval-based AI Algorithm that Infers User Preference by Querying the LLMs appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #TechNews #Technology [Source: AI Techpark]