


Natural Language Processing (NLP) seeks to enable computers to comprehend and interact using human language. A critical challenge in NLP is evaluating language models (LMs), which generate responses across various tasks. The diversity of these tasks makes it difficult to assess the quality of responses effectively. With the increasing sophistication of LMs, such as GPT-4, proprietary models often provide strong evaluation capabilities but suffer from transparency, control, and cost issues. This necessitates the development of reliable open-source alternatives that can effectively judge language outputs without compromising on these aspects.
The problem is multifaceted, involving the evaluation of responses and the scalability of evaluation mechanisms. Existing evaluation tools, particularly open-source models, have several limitations. Many models fail to provide direct assessment and pairwise ranking functionalities, the two most prevalent evaluation forms. This limits their adaptability to diverse real-life scenarios. They prioritize general attributes like helpfulness and harmlessness while issuing scores that significantly diverge from human evaluations. This inconsistency leads to unreliable assessments and requires improved evaluator models that closely mirror human judgments.
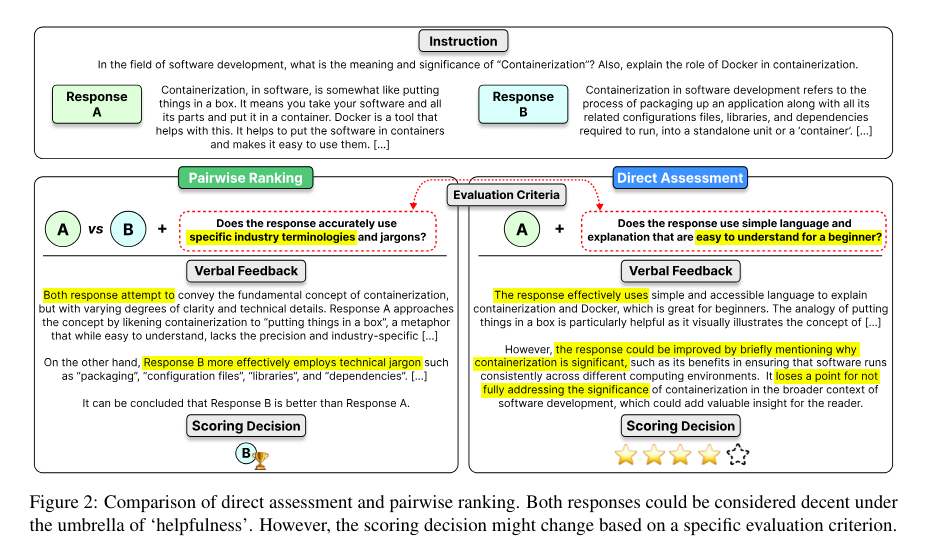
Research teams have attempted to address these gaps through various methods. However, most approaches lack comprehensive flexibility and fail to simulate human assessments accurately. Current proprietary models like GPT-4 remain expensive and non-transparent, which impedes widespread evaluation usage. The research team from KAIST AI, LG AI Research, Carnegie Mellon University, MIT, Allen Institute for AI, and the University of Illinois Chicago introduced Prometheus 2, a novel open-source evaluator designed to assess language models to resolve it. This model was developed to provide transparent, scalable, and controllable assessments while matching the evaluation quality of proprietary models.
Prometheus 2 was developed by merging two evaluator LMs: one trained exclusively for direct assessment and another for pairwise ranking. The merging of these models created a unified evaluator that excels in both evaluation formats. The researchers utilized the newly developed Preference Collection dataset, which features 1,000 evaluation criteria, to refine the model’s capabilities further. By effectively combining the two training formats, Prometheus 2 can evaluate LM responses using direct assessment and pairwise ranking methods. The merged model leverages a linear merging approach to blend the strengths of both evaluation formats, achieving high performance across evaluation tasks.
The model demonstrated the highest correlation with human and proprietary evaluators in benchmarking tests on four direct assessment benchmarks: Vicuna Bench, MT Bench, FLASK, and Feedback Bench. Pearson correlations exceeded 0.5 on all benchmarks, reaching 0.878 and 0.898 on the Feedback Bench for the 7B and 8x7B models, respectively. On four pairwise ranking benchmarks, including HHH Alignment, MT Bench Human Judgment, Auto-J Eval, and Preference Bench, Prometheus 2 outperformed existing open-source models, achieving accuracy scores surpassing 85%. The Preference Bench, an in-domain test set for Prometheus 2, indicated the model’s robustness and versatility.

Prometheus 2 narrowed the performance gap with proprietary evaluators, such as GPT-4, across various benchmarks. The model halved the correlation difference between humans and GPT-4 on the FLASK benchmark and achieved 84% accuracy in HHH Alignment evaluations. This highlights the significant potential of open-source evaluators to replace expensive proprietary solutions while ensuring comprehensive and accurate assessments.

In conclusion, the lack of transparent, scalable, and adaptable language model evaluators closely reflecting human judgment is a significant challenge in NLP. Researchers developed Prometheus 2, a novel open-source evaluator, to address it. They used a linear merging approach, combining two models trained separately on direct assessment and pairwise ranking. This unified model surpassed previous open-source models in benchmarking tests, showcasing high accuracy and correlation while substantially closing the performance gap with proprietary models. Prometheus 2 represents a significant advancement in open-source evaluation, offering a robust alternative to proprietary solutions.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
The post Prometheus 2: An Open Source Language Model that Closely Mirrors Human and GPT-4 Judgements in Evaluating Other Language Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]