


The development of natural language processing has been significantly propelled by the advancements in large language models (LLMs). These models have showcased remarkable performance in tasks like translation, question answering, and text summarization, proving their efficiency in generating high-quality text. However, despite their effectiveness, one major limitation remains their slow inference speed, which hinders their use in real-time applications. This challenge predominantly arises from the memory bandwidth bottleneck rather than a lack of computational power, leading to researchers seeking innovative ways to speed up their inference process.
The key issue lies in the conventional speculative decoding methods that rely on training separate draft models for faster text generation. These methods typically generate multiple tokens in parallel to accelerate the overall process. Although effective, they come with significant training costs and high latency. The high inference latency associated with these methods is primarily due to their dependence on external drafter models, which introduce additional computations that slow down the process.
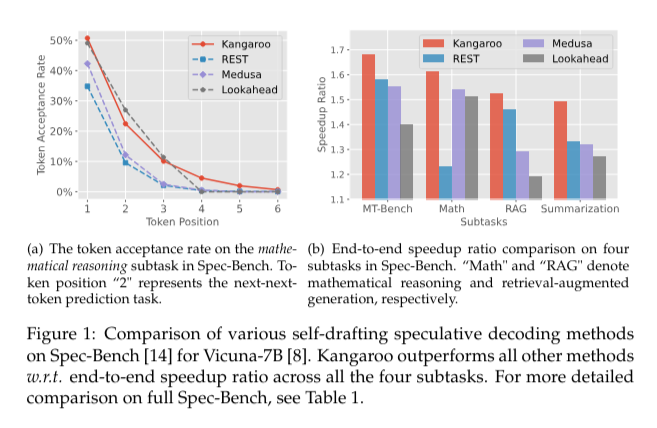
Current methods like Medusa and Lookahead have been designed to introduce more efficient speculative decoding approaches. These approaches aim to train smaller draft models that can work alongside the main language model. However, these methods still face latency issues, as the draft models require substantial computational resources and parameter updates. This slows down the overall inference process, reducing the effectiveness of the acceleration.
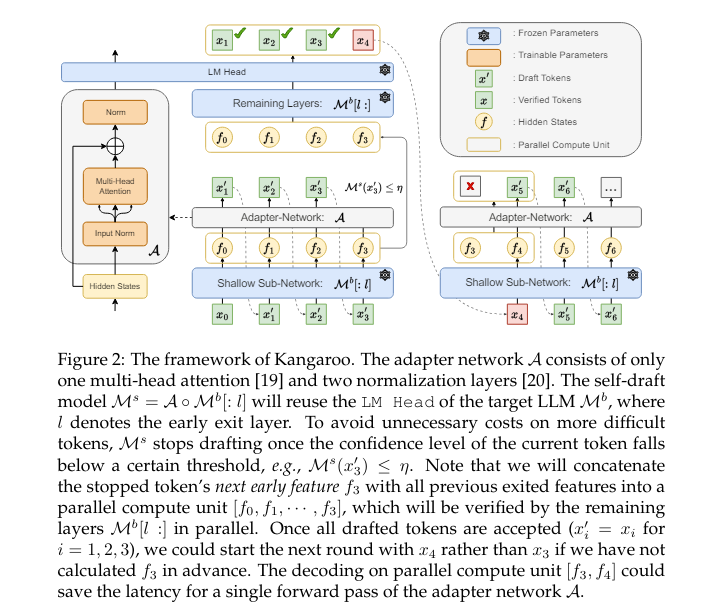
Huawei Noah’s Ark Lab researchers have developed an innovative framework named Kangaroo. This novel method addresses the issue of high latency in speculative decoding by introducing a lossless self-speculative decoding framework. Unlike traditional methods that rely on external drafter models, Kangaroo uses a fixed shallow LLM sub-network as the draft model. Researchers train a lightweight adapter module that connects the two to bridge the gap between the sub-network and the full model, enabling efficient and accurate token generation.
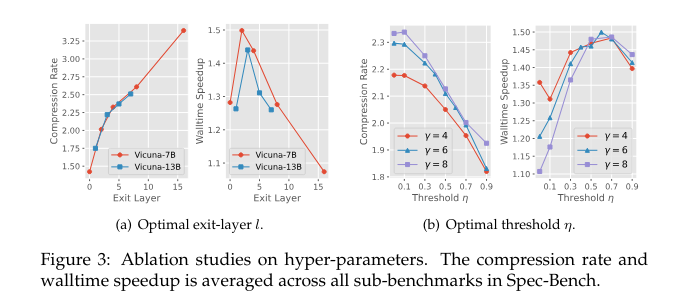
Kangaroo employs an early-exiting mechanism to enhance its efficiency further. This mechanism halts the small model’s prediction once the confidence level of the current token falls below a specific threshold, reducing unnecessary computational latency. The adapter module used in Kangaroo comprises a multi-head attention mechanism and two normalization layers, providing sufficient capacity to ensure high-quality token generation. The early exiting layer balances the token acceptance rate and drafting efficiency trade-offs. The dynamic mechanism of the Kangaroo allows for more efficient token generation by utilizing parallel computing and avoiding unnecessary computations.
Extensive experiments conducted using Spec-Bench demonstrate the Kangaroo’s effectiveness. It achieved a speedup ratio of up to 1.7× compared to other methods, using 88.7% fewer additional parameters than Medusa, which has 591 million additional parameters. Kangaroo’s significant improvements in speedup ratio are attributed to its double early-exit mechanism and the efficient design of the adapter network. This innovative framework significantly reduces latency, making it highly suitable for real-time natural language processing applications.
In conclusion, Kangaroo is a pioneering solution in accelerating LLMs’ inference speed. Using a fixed shallow sub-network from the LLM as a draft model, Kangaroo eliminates the need for costly and time-consuming external drafter models. Introducing the early-exit mechanism further enhances the speed and efficiency of the inference process, enabling Kangaroo to outperform other speculative decoding methods. With up to a 1.7× speedup and a drastic reduction in additional parameters, Kangaroo presents a promising approach to improving the efficiency of large language models. It sets a new standard in real-time natural language processing by significantly reducing latency without compromising accuracy.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post Huawei AI Introduces ‘Kangaroo’: A Novel Self-Speculative Decoding Framework Tailored for Accelerating the Inference of Large Language Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]