


Large Language Models (LLMs) have transformed numerous AI applications, but they come with high operational costs during inference phases due to the computational power they require. Efficiency in LLMs remains a primary challenge as their size and complexity increase. The key issue is the computational expense of running these models, particularly during the inference stage. This problem is exacerbated by the models’ dense activation patterns, which demand substantial computational resources.
Existing research includes approaches like quantization, notably explored in BinaryBERT, and pruning techniques to enhance model efficiency. A mixture of Expert (MoE) frameworks, exemplified by GShard and Switch Transformers, dynamically allocate computational resources. Activation sparsity is promoted through methods like ReLU in large models. Hardware-aware optimizations, as shown in works by Kim et al., emphasize the importance of software-hardware synergy, with custom GPU kernels playing a crucial role in applying theoretical sparsity practically, leading to real-time computational savings in neural network operations.
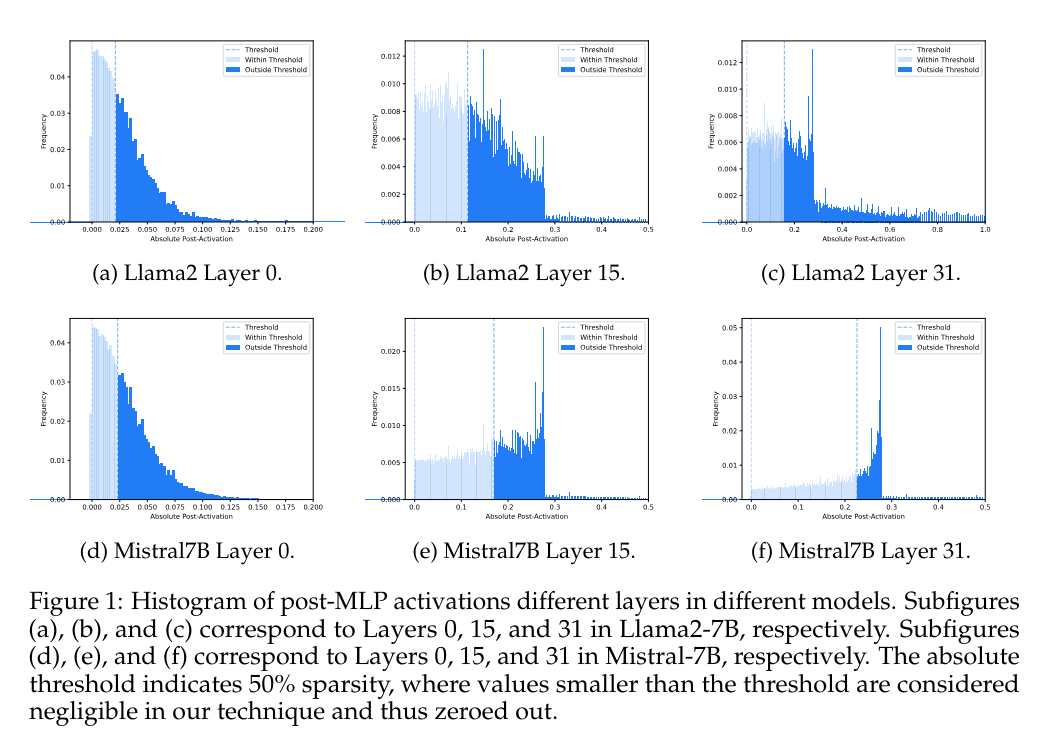
Researchers from Oxford University, University College London, and Stanford University have introduced Contextually Aware Thresholding for Sparsity (CATS), a novel framework to enhance the operational efficiency of LLMs. Unlike traditional methods, which often compromise model performance, CATS strategically applies a non-linear activation function that dynamically adjusts neuron activation based on input context. This targeted approach to sparsity maintains high accuracy levels while significantly reducing computational overhead.
CATS employs a two-step methodology, beginning with precisely determining neuron relevance through a context-sensitive threshold. This method was rigorously tested on popular LLMs like Mistral-7B and Llama2-7B using datasets like RefinedWeb. The practical application of sparsity was facilitated by a custom GPU kernel tailored to optimize the sparse activations efficiently and effectively during model inference. This direct focus on contextual relevance and hardware-specific optimization sets CATS apart from previous sparsity approaches, making it a reassuringly valuable tool for real-world AI deployment.
Implementing CATS has produced measurable and impressive improvements in computational efficiency and model performance. In tests conducted with Mistral-7B and Llama2-7B, CATS maintained performance within 1-2% of the full-activation baseline while achieving up to 50% activation sparsity. Specifically, CATS reduced wall-clock inference times by approximately 15%, a significant and impressive gain in efficiency. These results confirm that CATS effectively balances the trade-off between sparsity and performance, providing a viable solution for reducing the operational costs of deploying large language models without sacrificing accuracy.
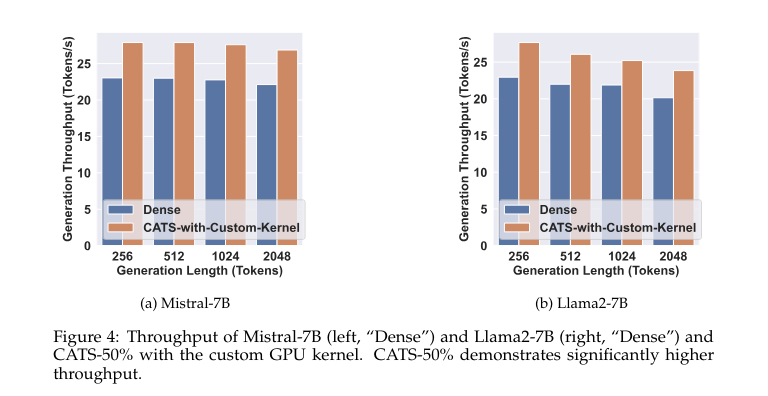
In conclusion, the CATS framework represents a significant step forward in optimizing LLMs. By incorporating a context-sensitive activation function, CATS effectively reduces computational demands while maintaining model performance. Its successful application to models like Mistral-7B and Llama2-7B and its ability to achieve substantial efficiency gains without sacrificing performance underscore its potential as a scalable solution for cost-effective AI deployment. This research offers a practical approach to addressing the resource-intensive nature of modern AI models, making it a valuable contribution to the field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post CATS (Contextually Aware Thresholding for Sparsity): A Novel Machine Learning Framework for Inducing and Exploiting Activation Sparsity in LLMs appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]