


Large Language Models (LLMs) stand out for their ability to parse and generate human-like text across various applications. These models have become integral to technologies that automate and enhance text-based tasks. Despite their advanced capabilities, modern LLMs face significant challenges in scenarios requiring intricate reasoning and strategic planning. These challenges stem from the limitations in current training methodologies, which rely heavily on vast amounts of high-quality, annotated data that are only sometimes available or feasible to gather.
Existing research includes advanced prompting techniques like GPT-4’s Chain-of-Thought, which improves reasoning by outlining intermediate steps. Some models demonstrate the potential of fine-tuning LLMs with high-quality data, although this approach is constrained by data availability. Self-correction strategies enable LLMs to refine outputs through internal feedback. Furthermore, Monte Carlo Tree Search (MCTS), as seen in strategic games like Go, has been adapted to enhance decision-making in language models such as AlphaZero.
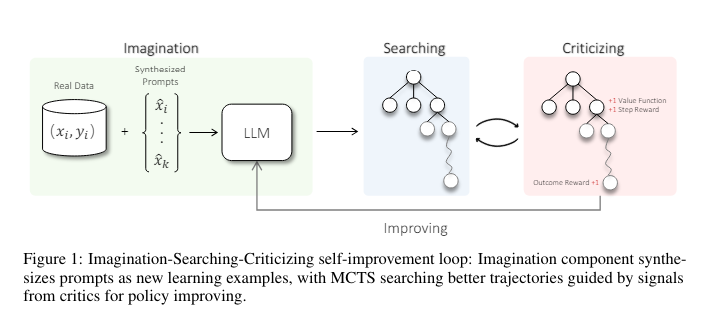
Researchers from Tencent AI lab have introduced ALPHALLM, a novel framework that integrates MCTS with LLMs to promote self-improvement without additional data annotations. This framework is distinct because it borrows strategic planning techniques from board games, applying them to the language processing domain, which allows the model to simulate and evaluate potential responses independently.
The ALPHALLM methodology is structured around three core components: the imagination component, which synthesizes new prompts to expand learning scenarios; the MCTS mechanism, which navigates through potential responses; and critic models that assess the efficacy of these responses. The framework was empirically tested using the GSM8K and MATH datasets, focusing on mathematical reasoning tasks. This method allows the LLM to enhance its problem-solving abilities by learning from simulated outcomes and internal feedback, optimizing the model’s strategic decision-making capabilities without relying on new external data.
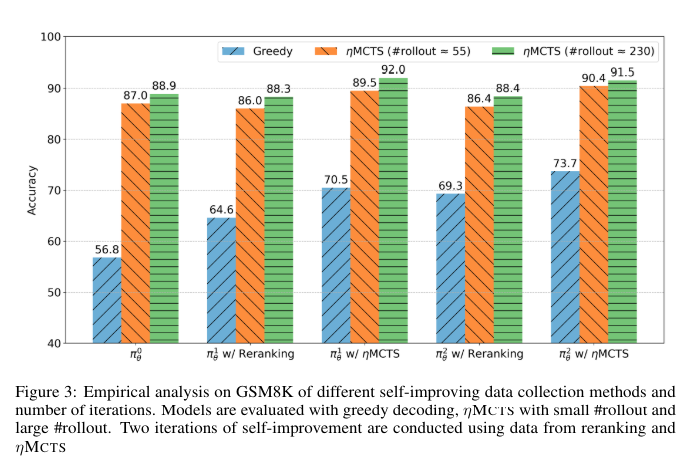
Empirical testing of ALPHALLM demonstrated significant performance improvements in mathematical reasoning tasks. Specifically, the model’s accuracy on the GSM8K dataset increased from 57.8% to 92.0%, and on the MATH dataset, it improved from 20.7% to 51.0%. These results validate the framework’s effectiveness in enhancing LLM capabilities through its unique self-improving mechanism. By leveraging internal feedback and strategic simulations, ALPHALLM achieves substantial gains in task-specific performance without additional data annotations.
In conclusion, the research introduced ALPHALLM, a framework that integrates MCTS with LLMs for self-improvement, eliminating the need for additional data annotations. By successfully applying strategic game techniques to language processing, ALPHALLM significantly enhances LLMs’ reasoning capabilities, as evidenced by its marked performance improvements on the GSM8K and MATH datasets. This approach not only advances the autonomy of LLMs but also underscores the potential for continuous, data-independent model enhancement in complex problem-solving domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post Tencent AI Lab Developed AlphaLLM: A Novel Machine Learning Framework for Self-Improving Language Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]